This is the project home for Auditory scene analysis as Bayesian inference in sound source models (2018). You can read a summary of this work here presented at CCN, our CogSci paper, or listen to a talk here. Lots of work has been done on this project since then, feel free to get in touch for an update!
The following links will bring you to audio for each illusion, along with samples from the model posterior distribution. Our model can also be applied to simple natural sounds, for which audio and posterior samples are included below as well. On all pages, you can click on gammatonegram pictures in order to hear the corresponding audio!
Some of the included soundclips (**) were made by Pierre Ahad and Albert Bregman for their 1966 CD, Demonstrations of Auditory Scene Analysis: The Perceptual Organization of Sound, or were adapted from those stimuli. The CD can be found here. See their full copyright notice at the bottom of this page.
How to read and listen to gammatonegrams
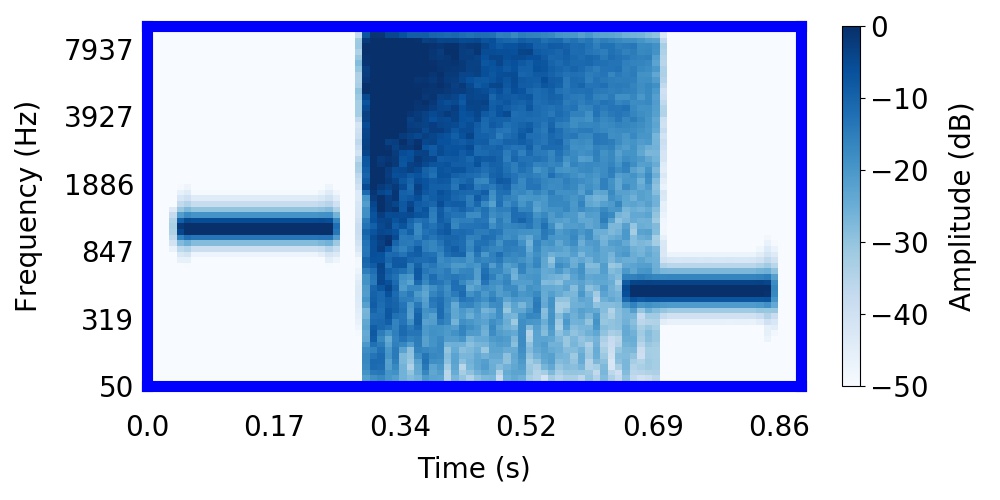
Gammatonegrams are a time-frequency representation of audio that is based on a filterbank model of the human ear, allowing us to visualise the amplitude (in dB, indicated by colour) of different sound frequencies over time. While listening to the sound, you can follow along on the gammatonegram almost like a musical score. Click the following gammatonegram to play the sound:
On this website, as in the paper, we display observed gammatonegrams in purple (model input) and renderings of the model's inferred scenes in blue (model output). If additional audio demonstrations accompany the observation, we also plot those in purple.
We used Dan Ellis' (2009) gammatone-like spectrograms for speedy rendering of gammatonegrams that could be used in MCMC inference. Back to top
Maddie Cusimano (m c u s i [at] mit dot edu) and Luke Hewitt (l b h [at] mit dot edu) are MIT graduate students behind this modeling effort, working in Josh McDermott's Lab for Computational Audition and Josh Tenenbaum's Computational Cognitive Science lab, respectively. Our generative model was implemented in WebPPL. This work also borrows auditory illusions from several different researchers, who are cited in the relevant sections.