The problem of sequential grouping is demonstrated in the figure to the right. An infinite number of sources could have combined to produce the observed audio. For instance, all of the tones could have been produced by a single source or they could be split up in several ways across two or three sources (A, B). Inferring tone elements from sound is also ill-posed, as multiple overlapping elements may combine to produce a long tone (C). Of course, this is just the simplest case: sequential grouping is not limited to tones and occurs in conjunction with the analysis sounds occuring simultaneously.
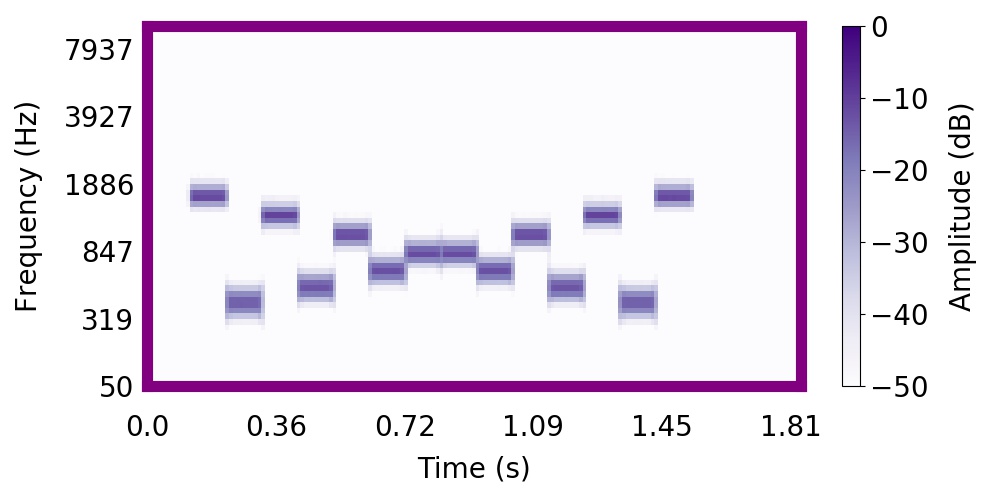
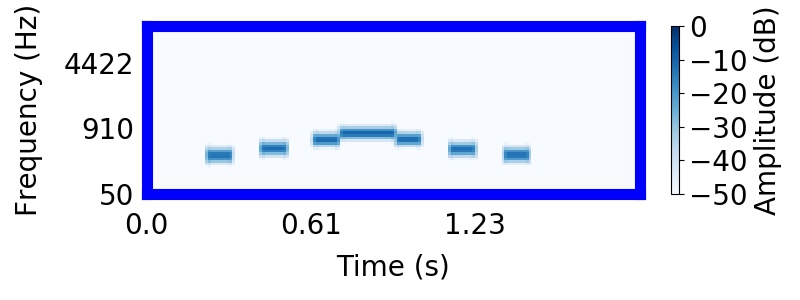
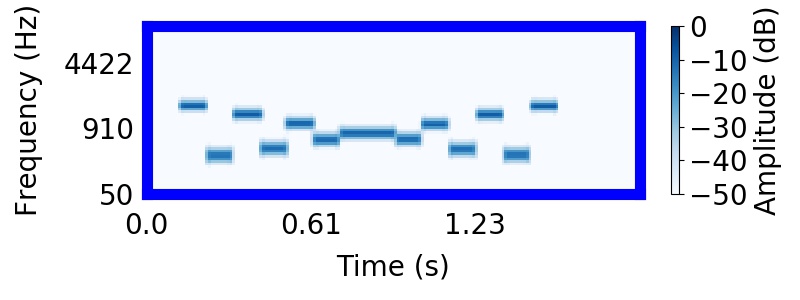
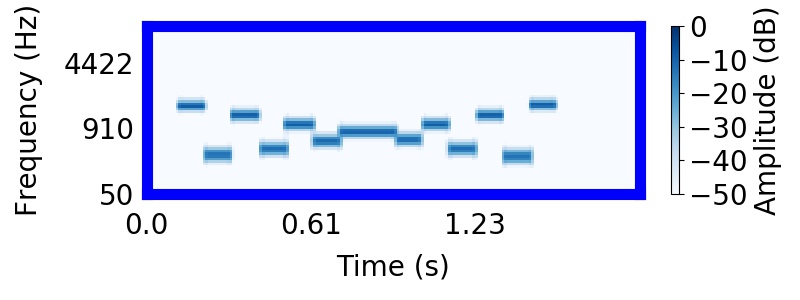
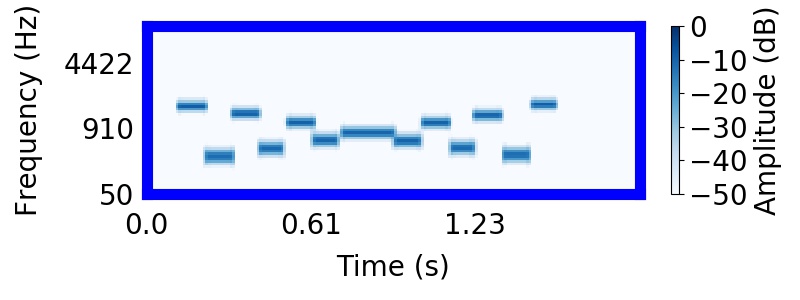
Tougas and Bregman (1985) interleaved rising and falling tone sequences, producing the 'X' pattern apparent below. They presented listeners with subsets of the tone elements in the 'X' pattern and asked them to rate how clearly the subset resembled something they heard in the tone sequence.
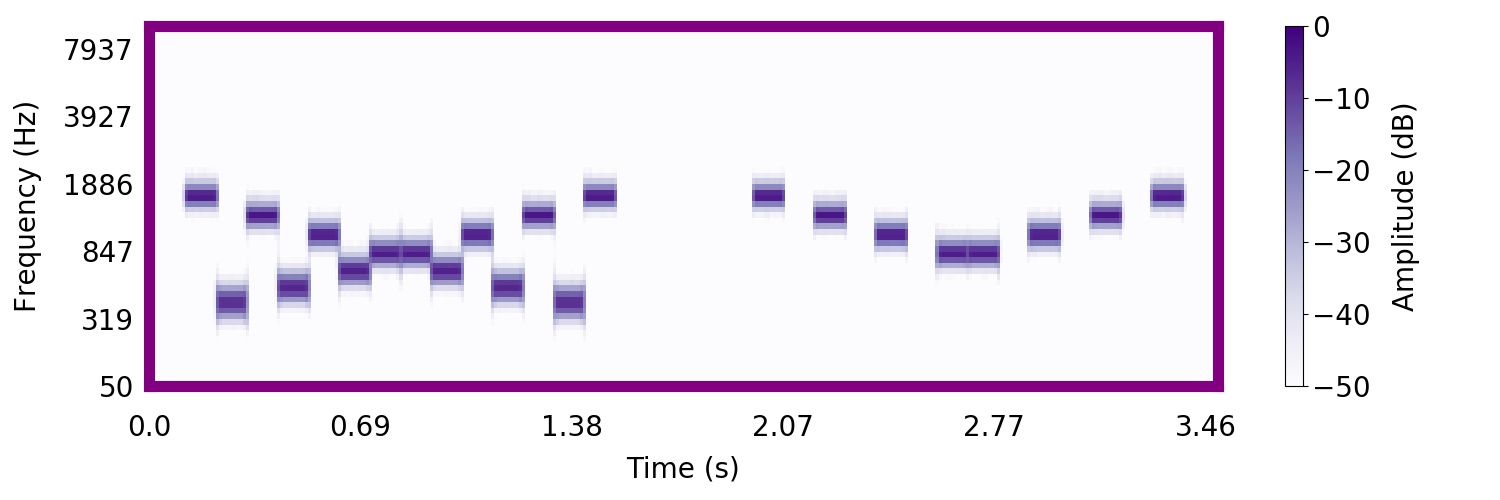
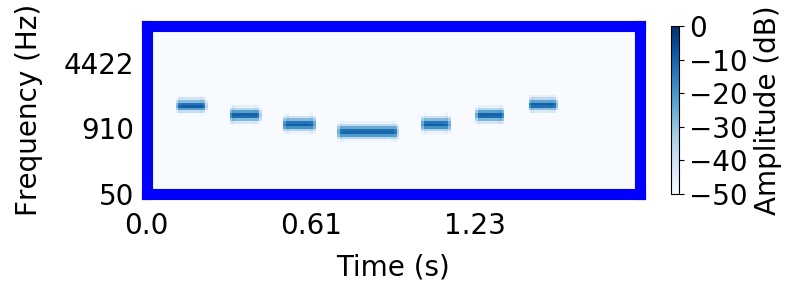
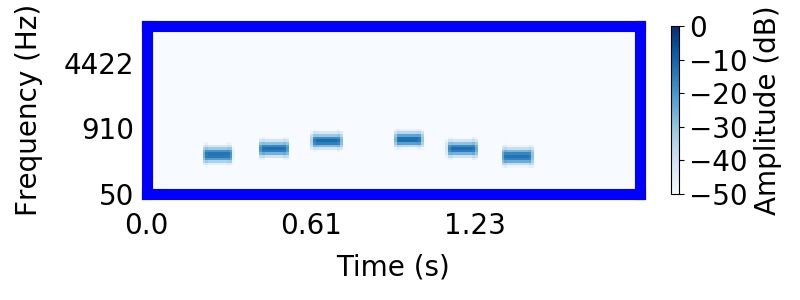
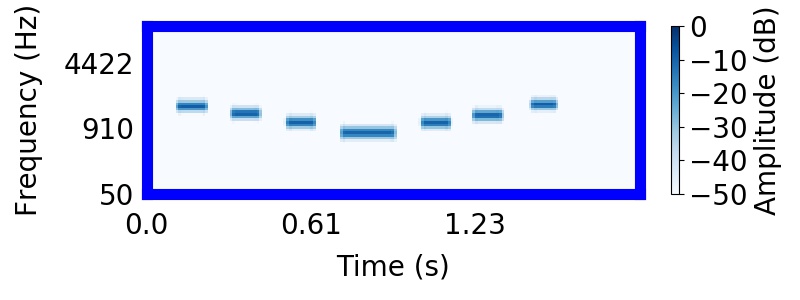
Listeners found it difficult to hear rising or falling trajectories in the mixture. Instead, listeners were strongly biased to hear the higher frequency tones as segregated from the lower frequency tones, producing two sequences that 'bounce' and return to their starting points. In the following sound, you will hear the entire 'X' pattern followed by the higher frequency 'bouncing' sequence.
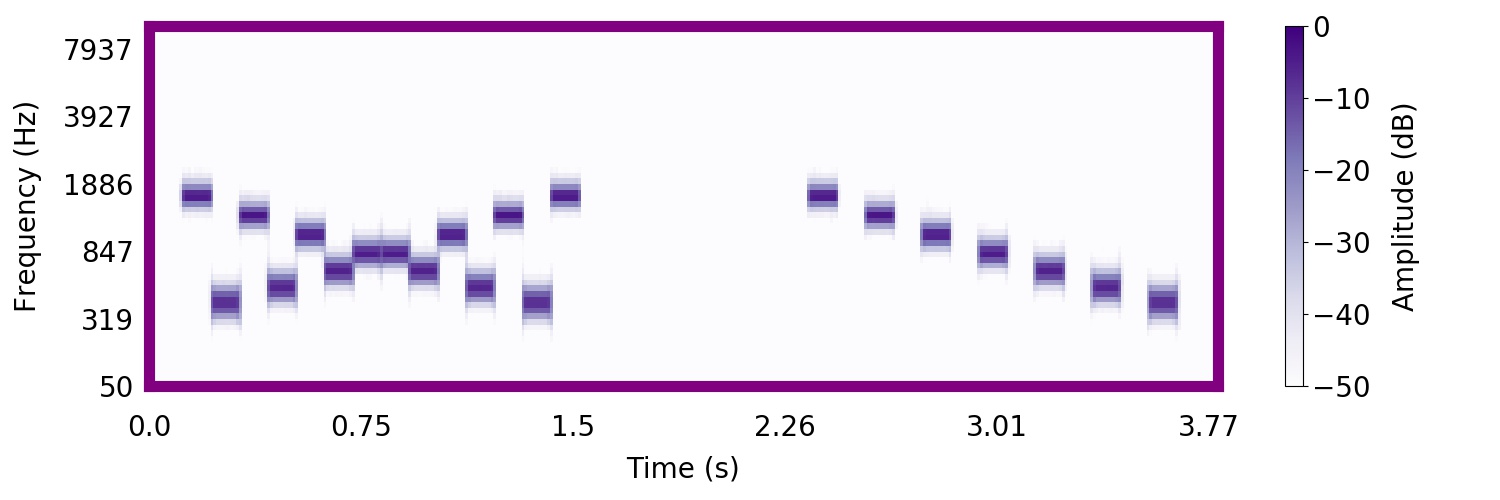
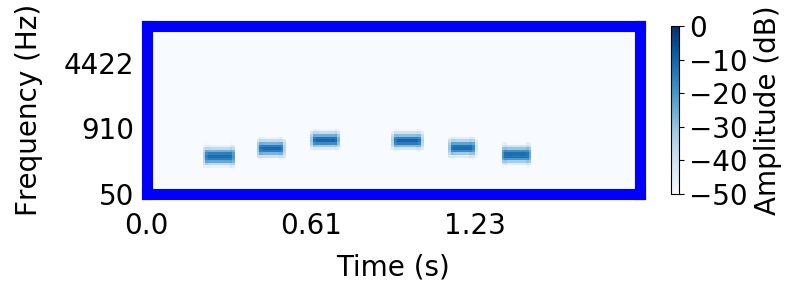
In this next sound, you will hear the entire 'X' pattern followed by the falling trajectory.
Most find that it is much easier to recognize that they heard the bouncing sequence in the mixture, rather than the trajectory.
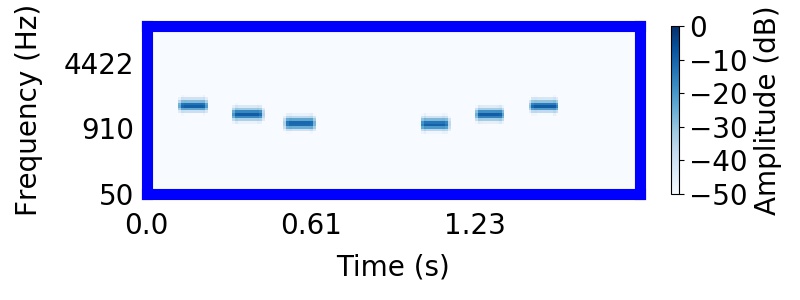
The model also prefers this grouping of tones into different sources.
Posterior samples of scenes
Mixture of sampled sources
Tougas, Y. & Bregman, A. S. (1985). Crossing of Auditory Streams. Journal of Experimental Psychology: Human Perception and Performance, 11(6), 788-798. Back to top Back to main