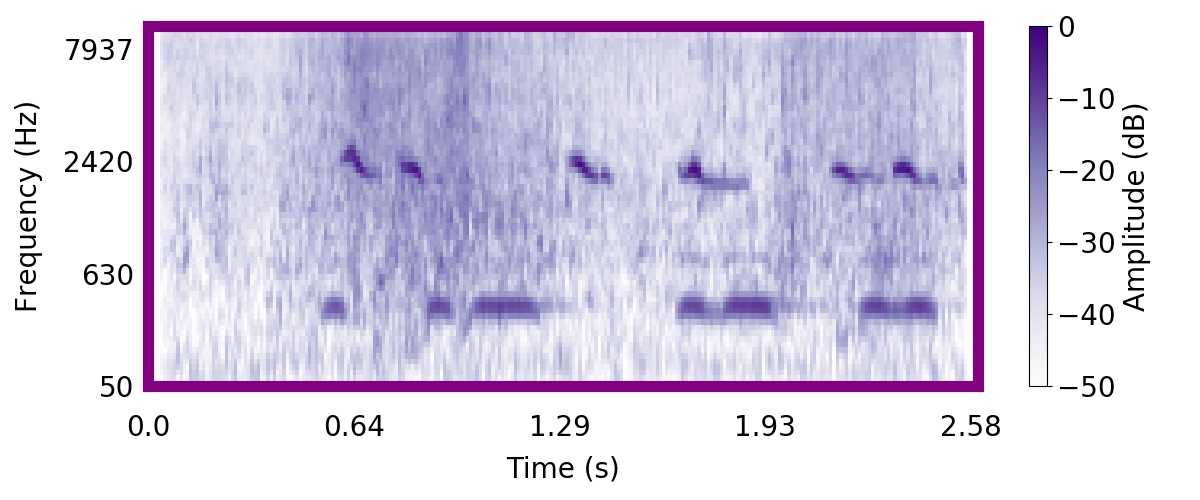
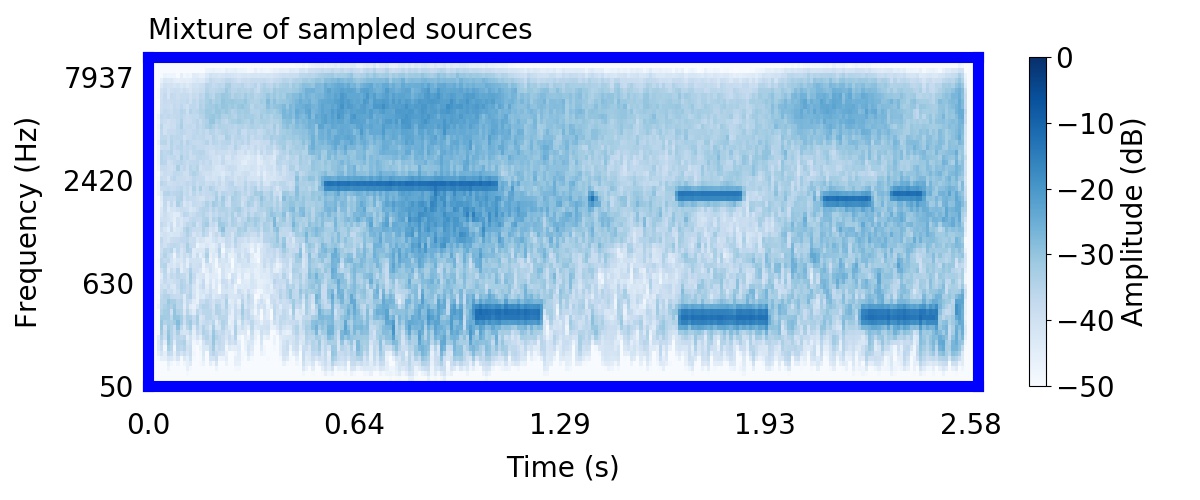
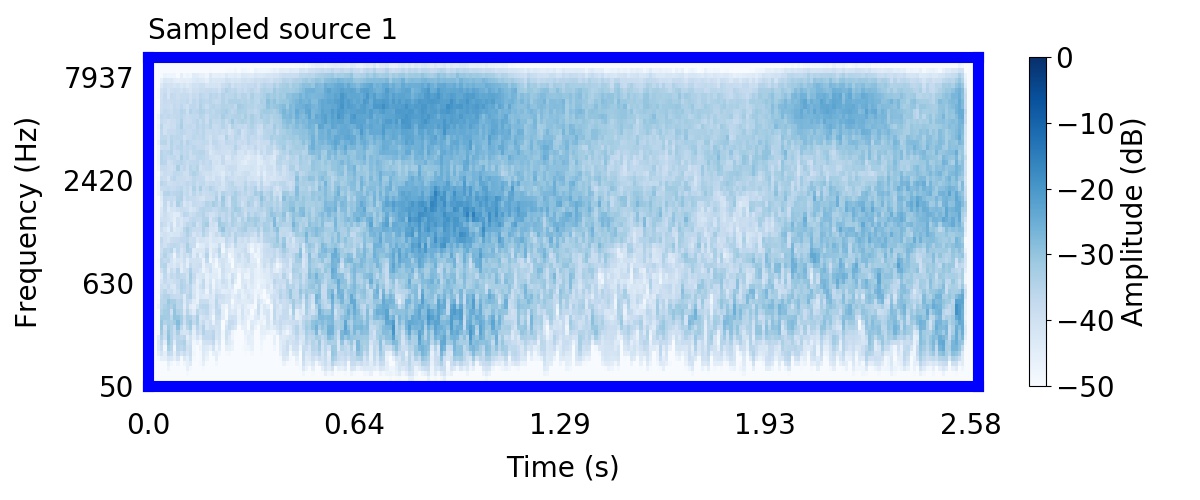
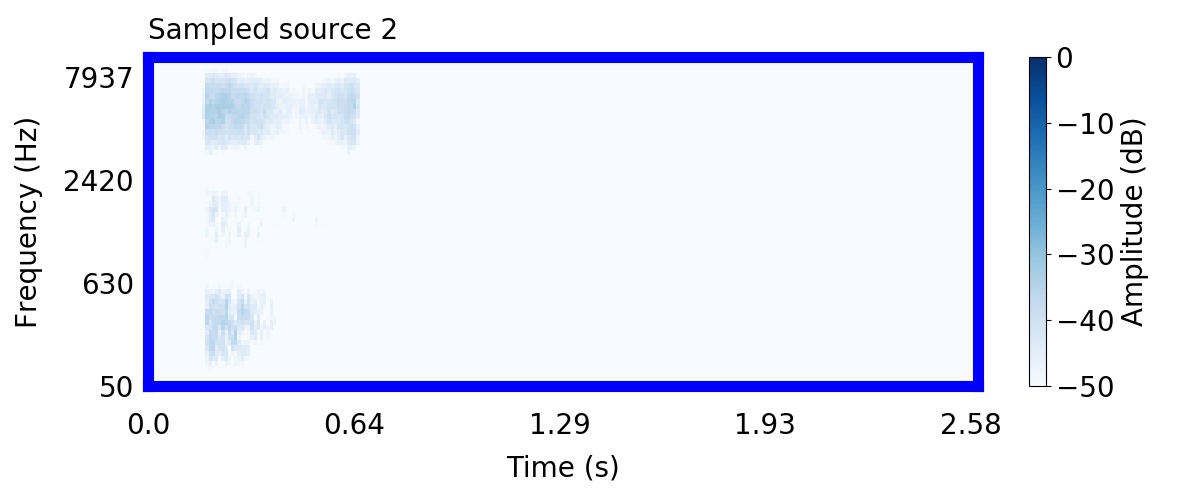
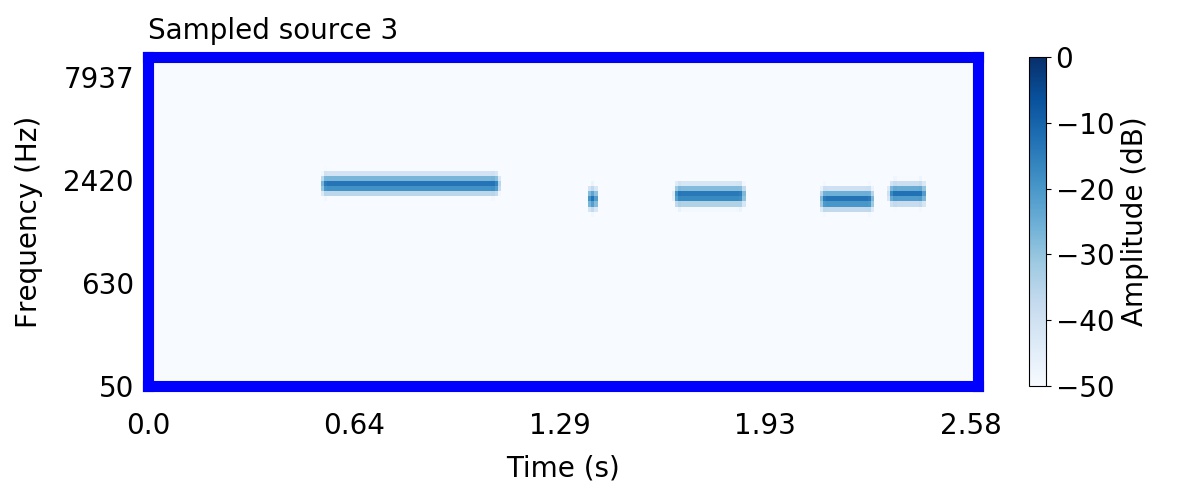
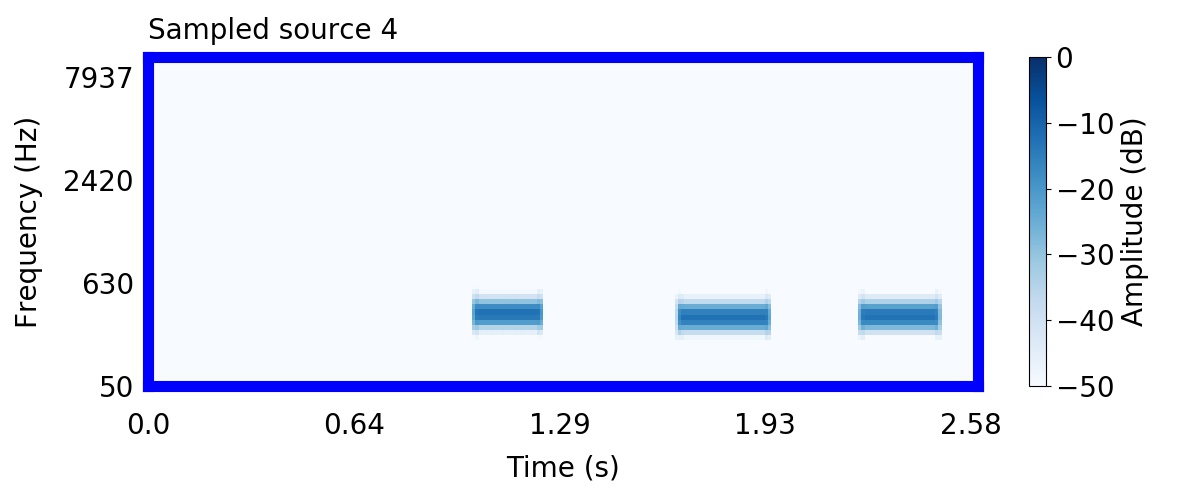
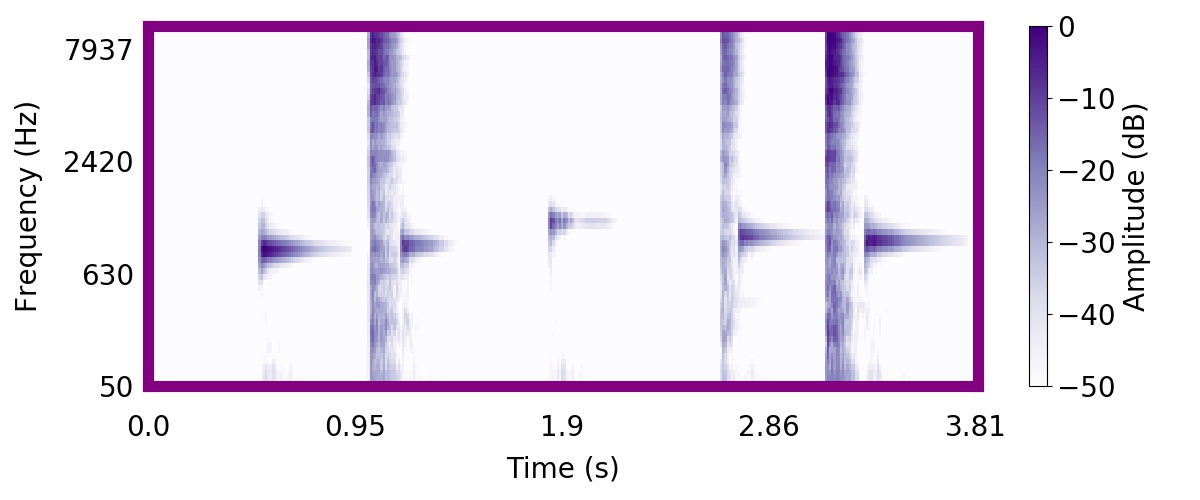
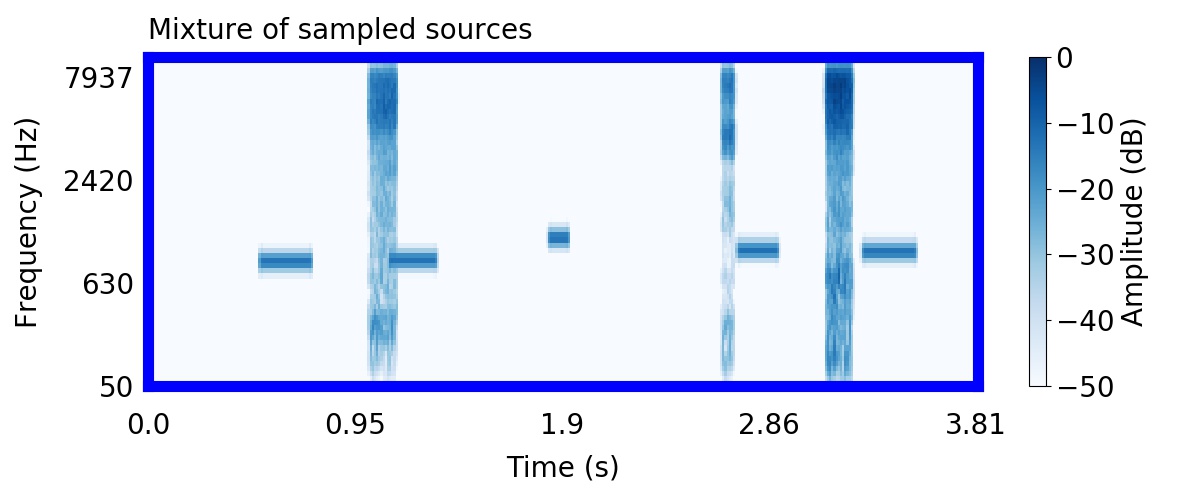
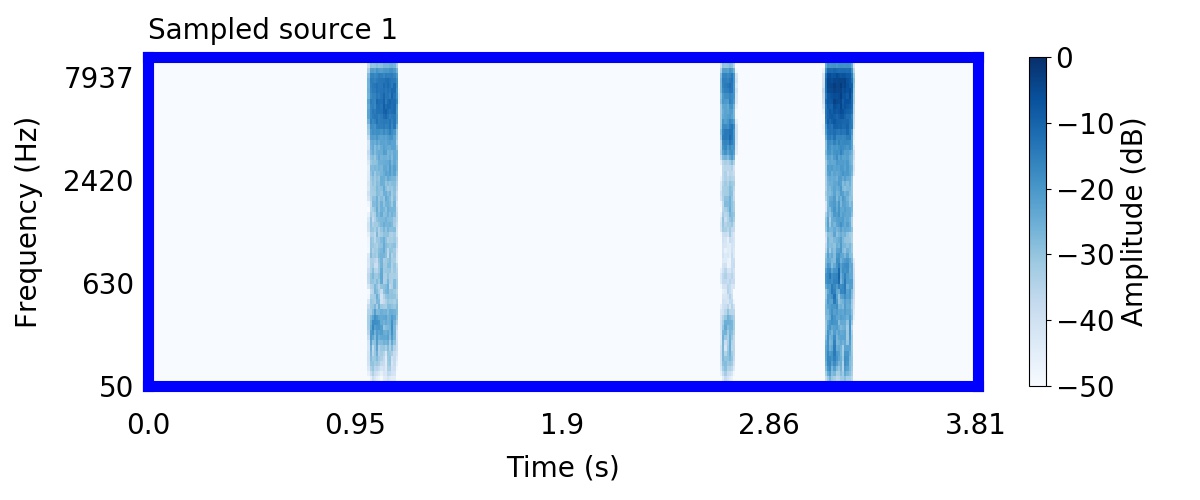
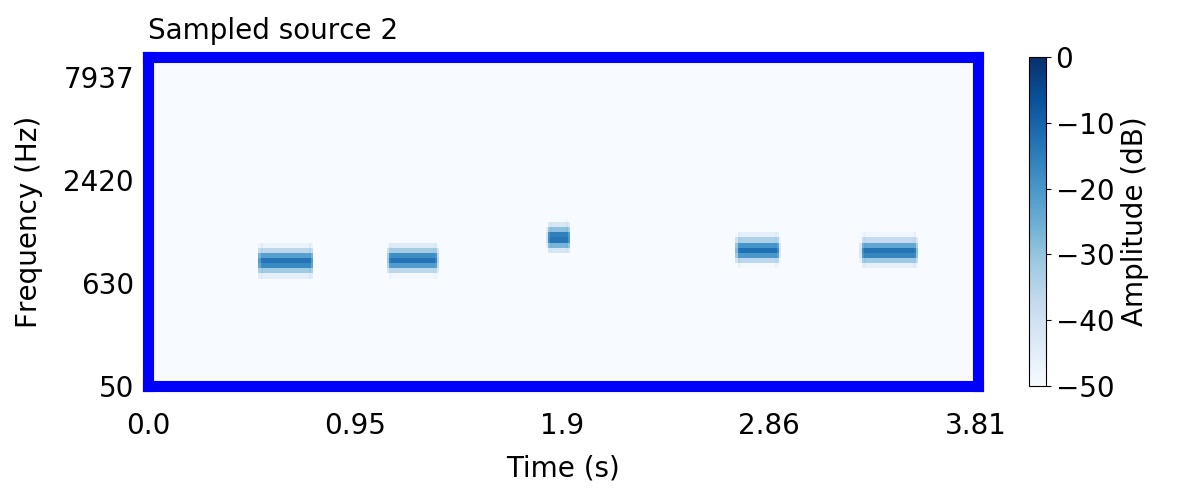
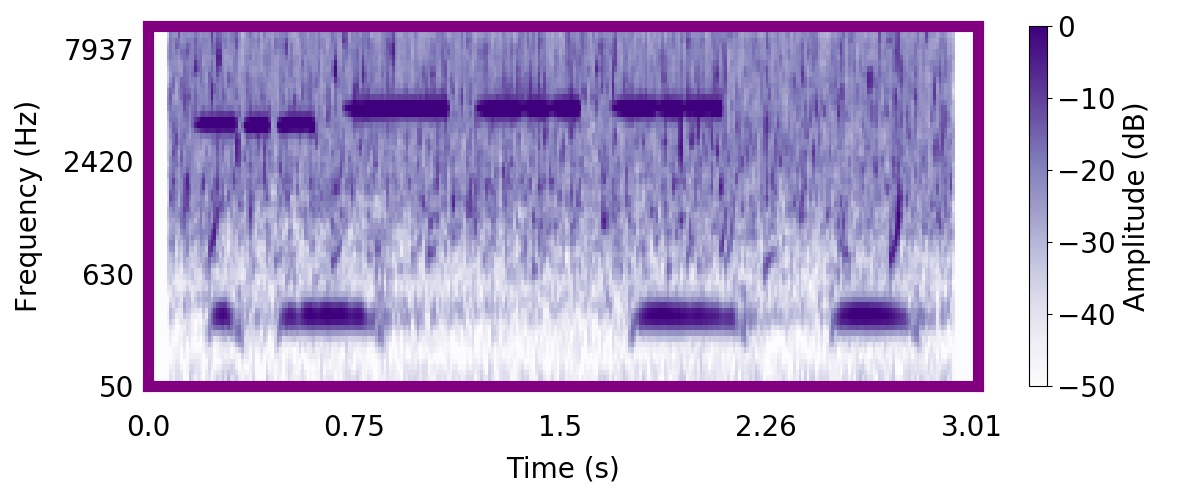
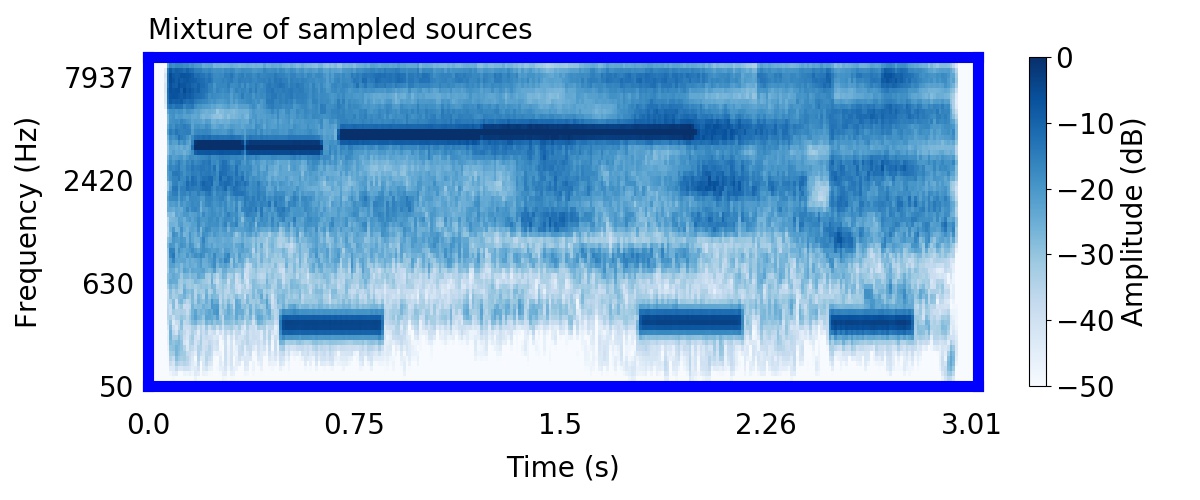
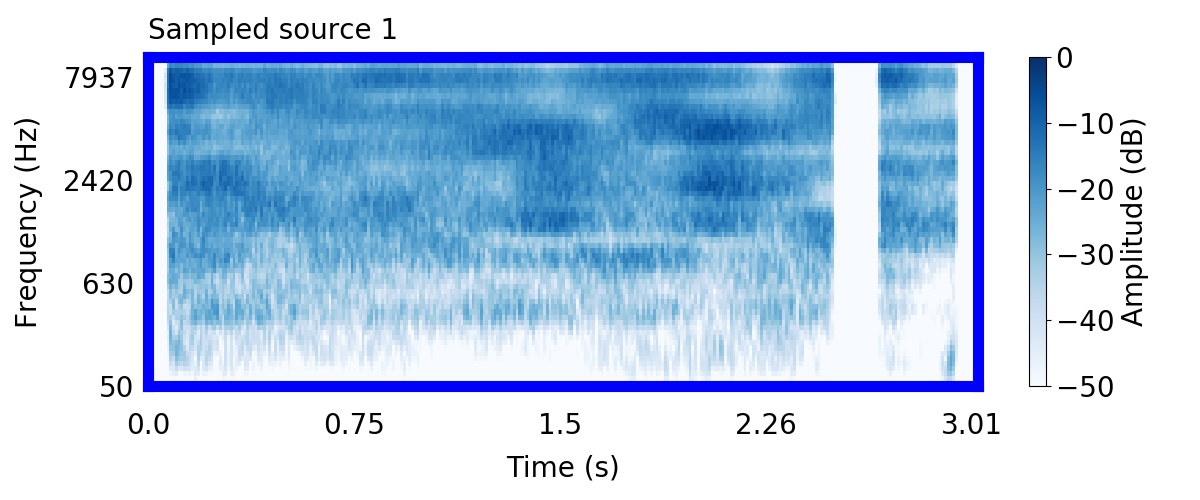
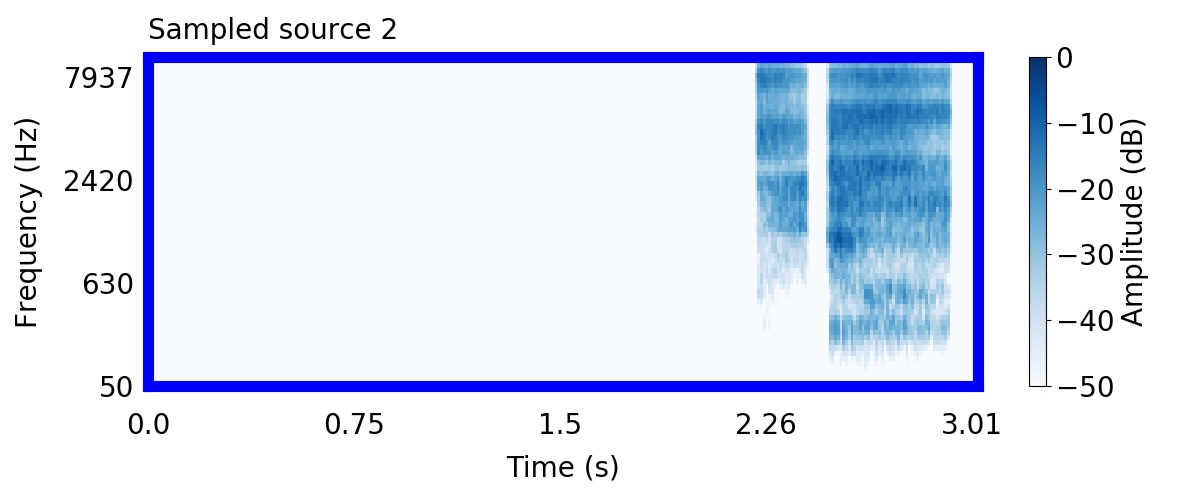
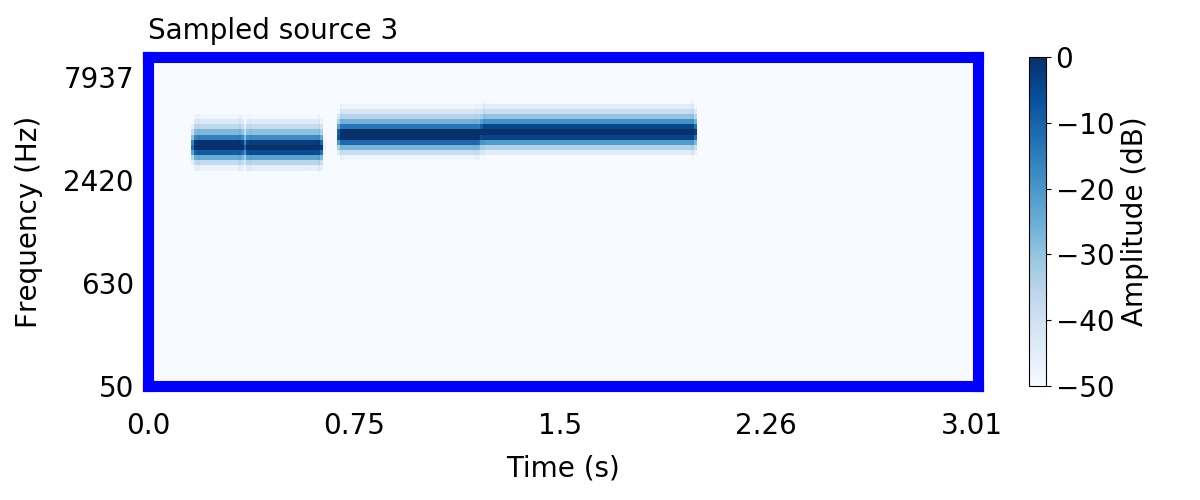
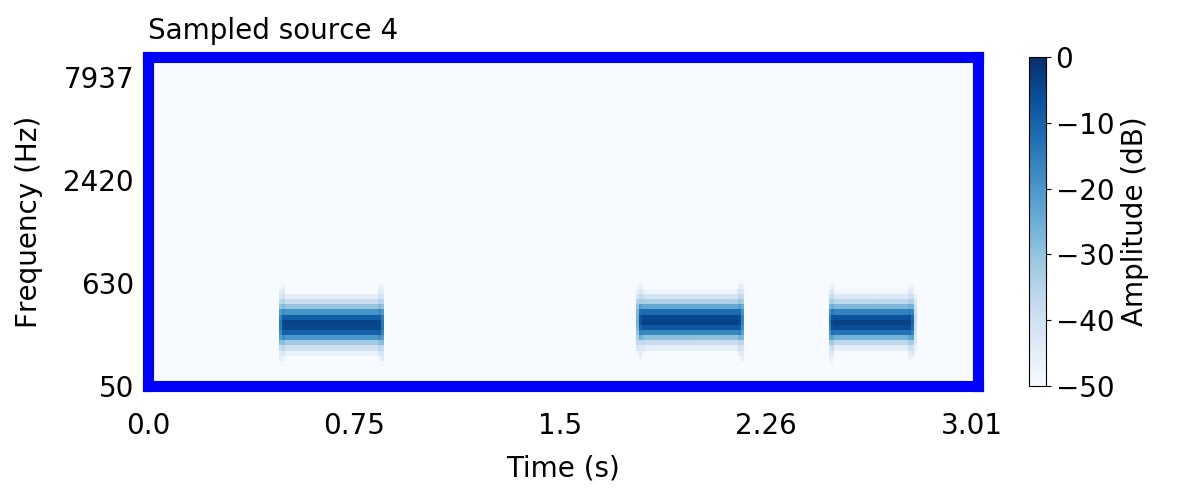
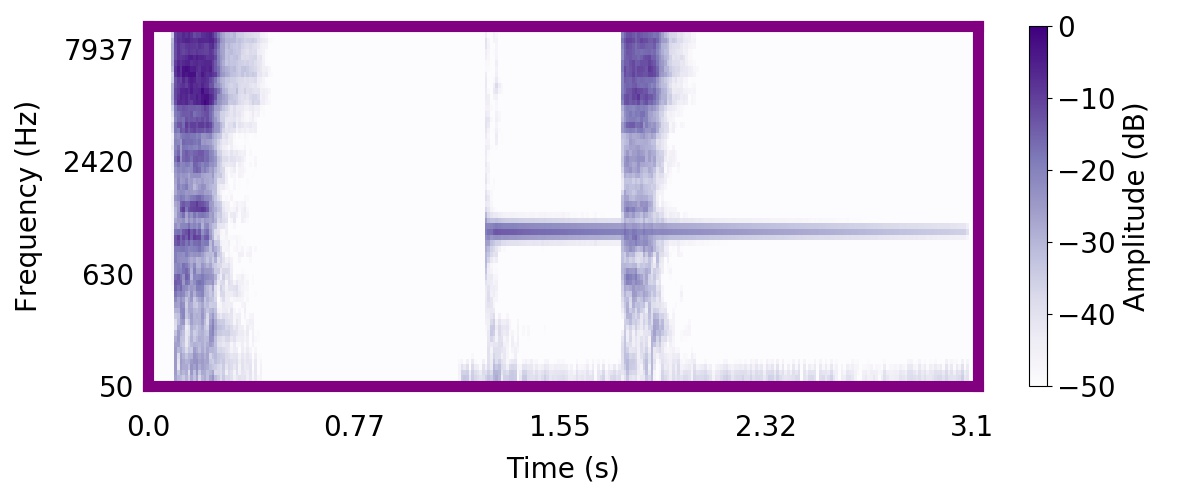
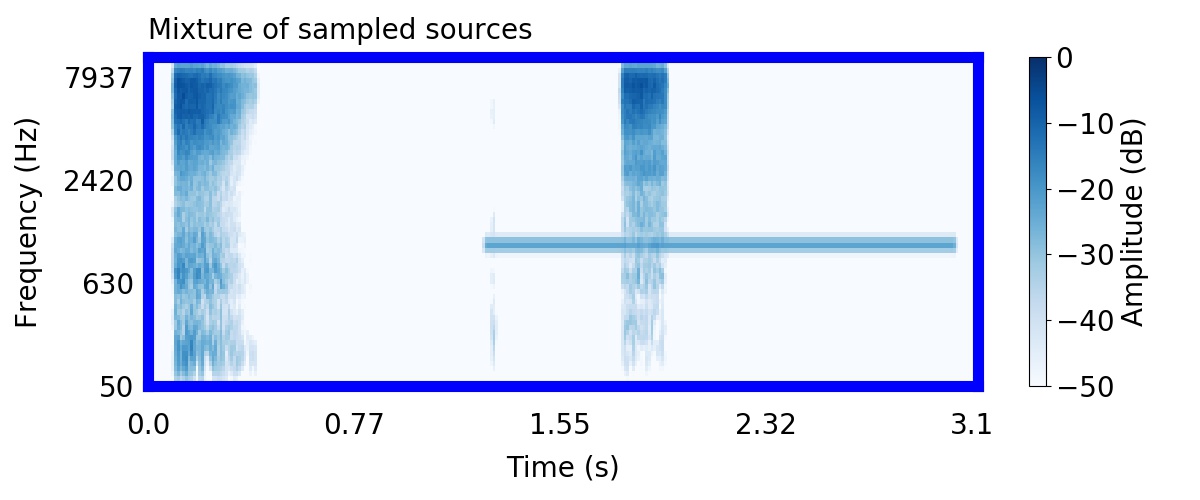
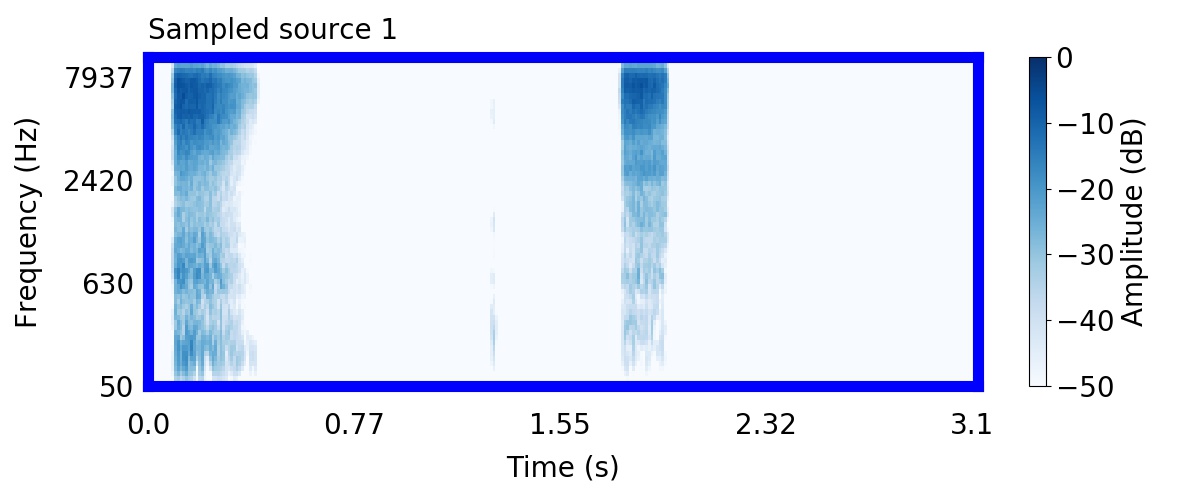
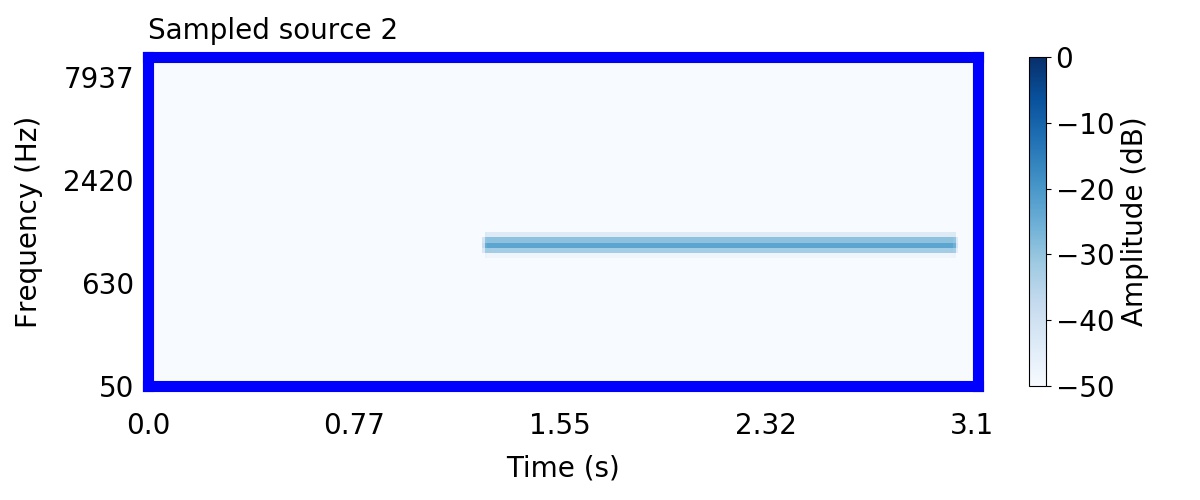
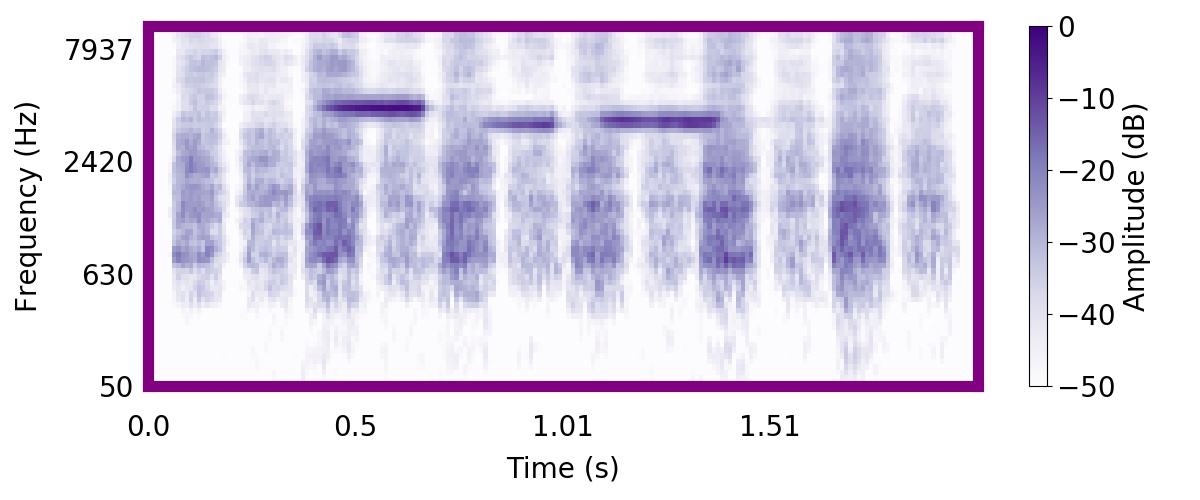
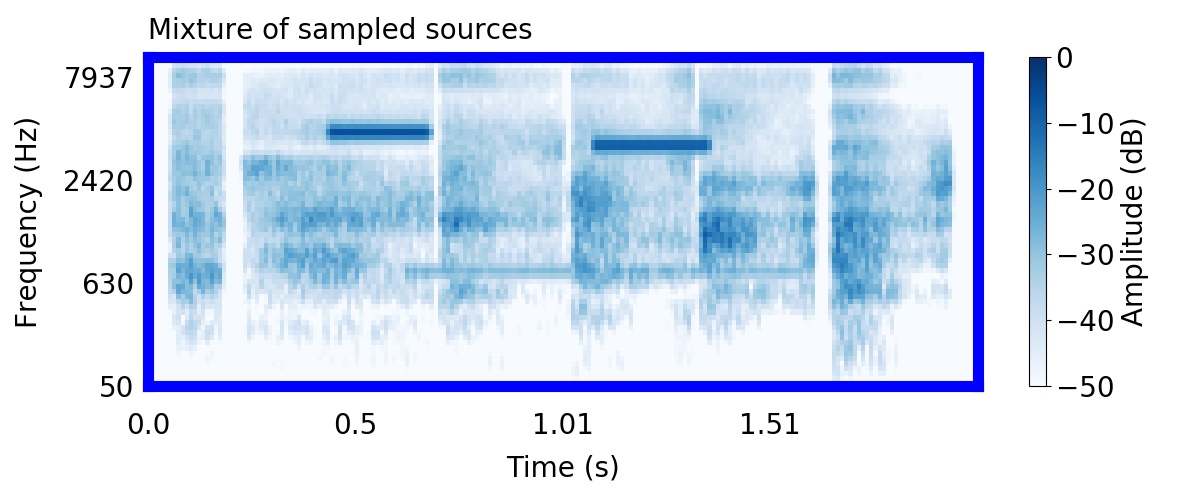
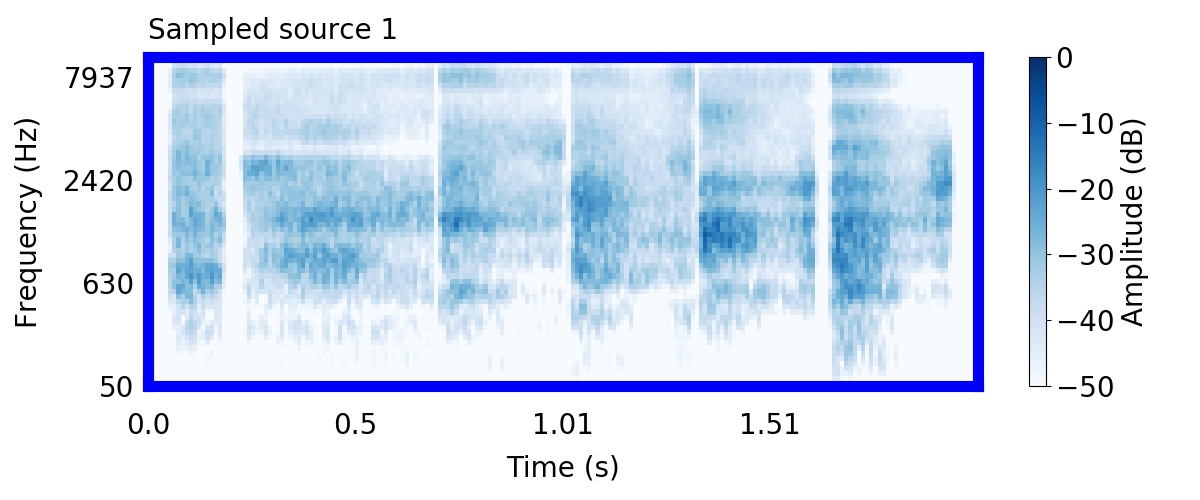
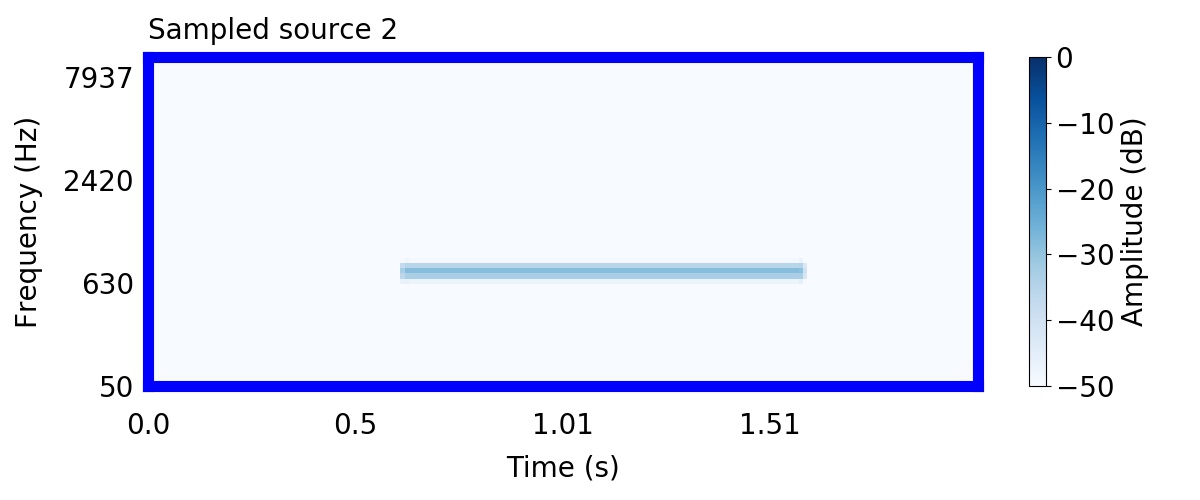
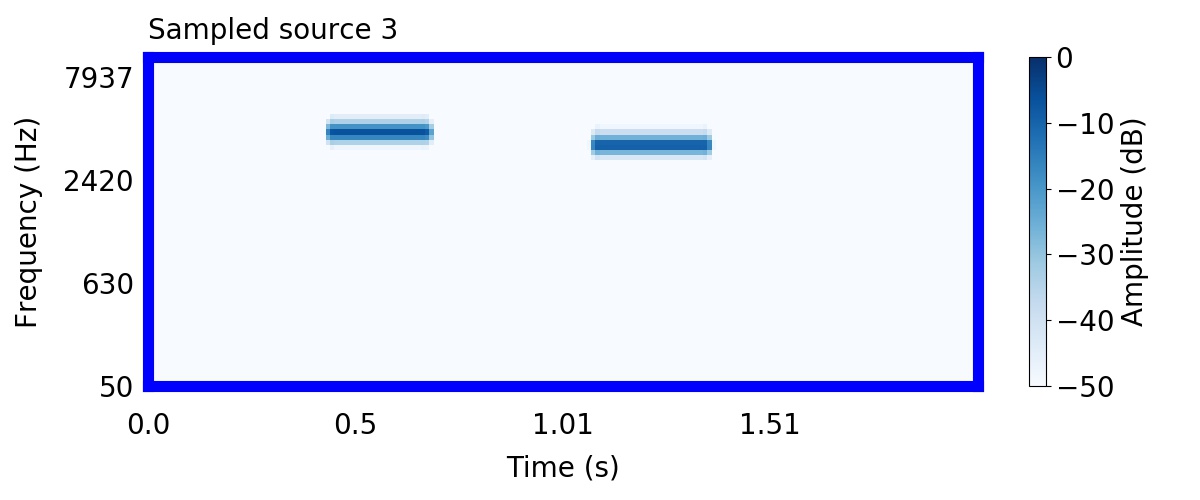
Unlike most other models of human auditory scene analysis, ours is a generative model on the acoustic waveform. This means that we can apply our model to arbitrary sounds, including recorded audio. Here we show preliminary model inferences on simple recorded audio.