| Posterior samples of scenes | Mixture of sampled sources | 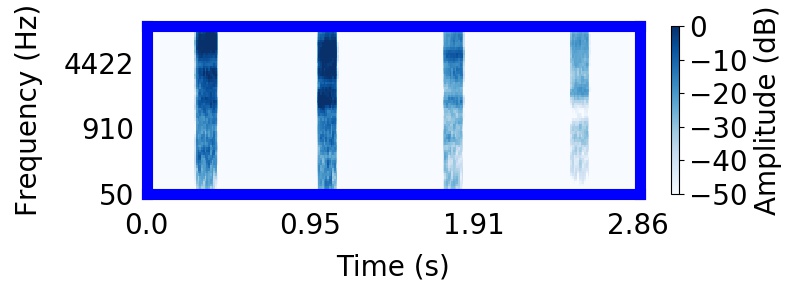 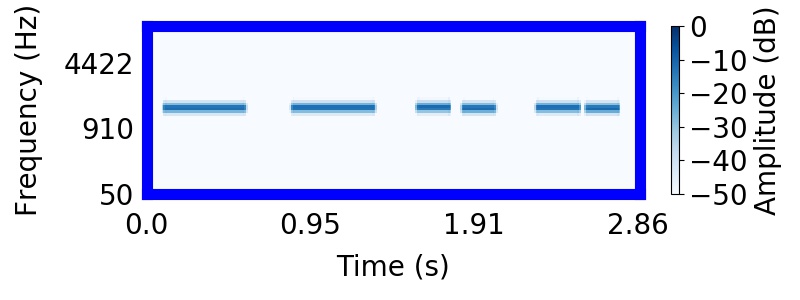
| 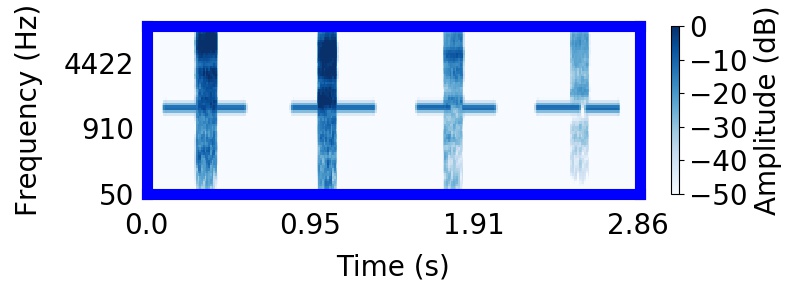 |
 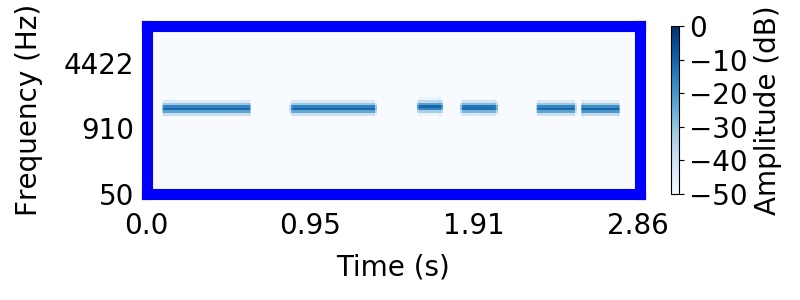 | 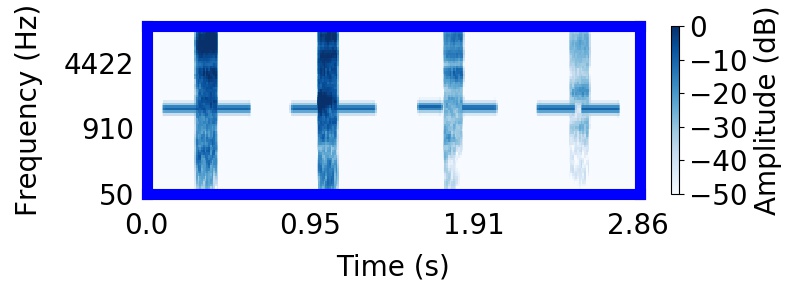 |
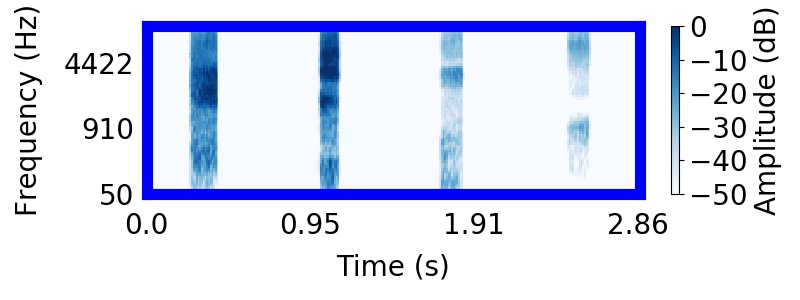 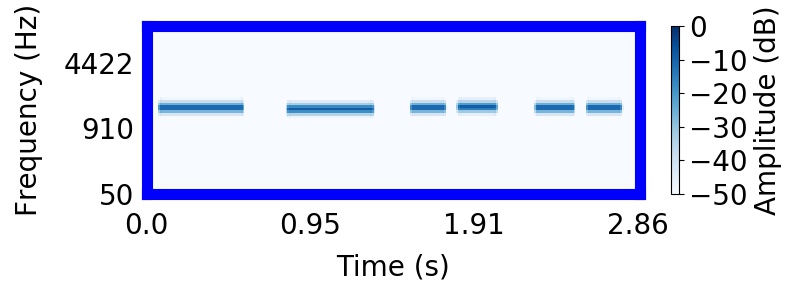 |  |
  |  |
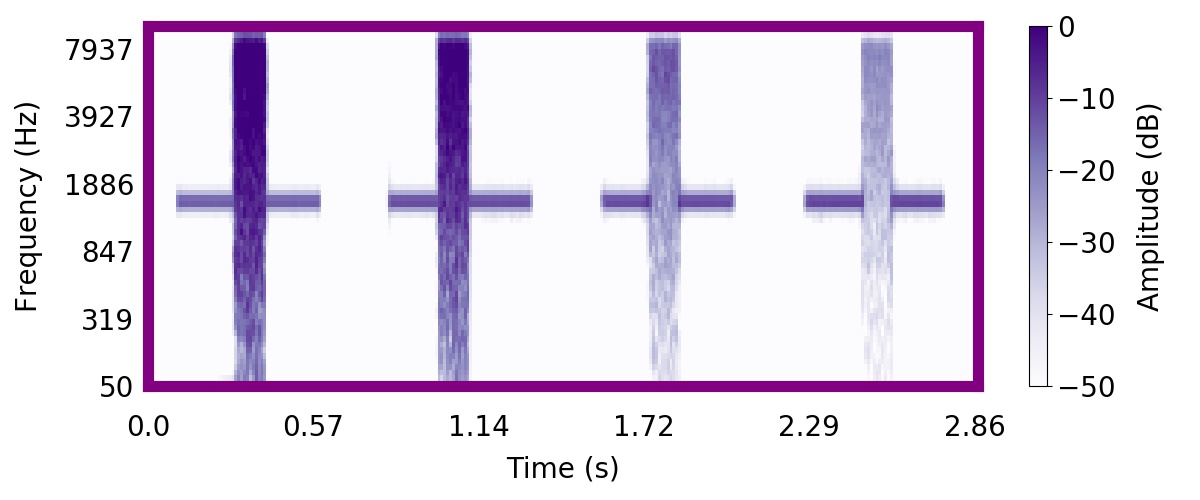
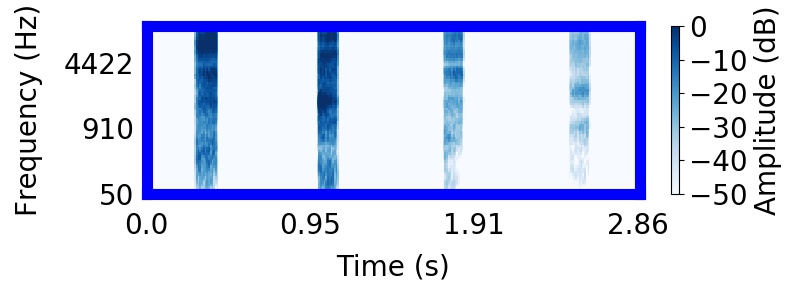
| Posterior samples of scenes | Mixture of sampled sources |
| |
| |
| |
| |
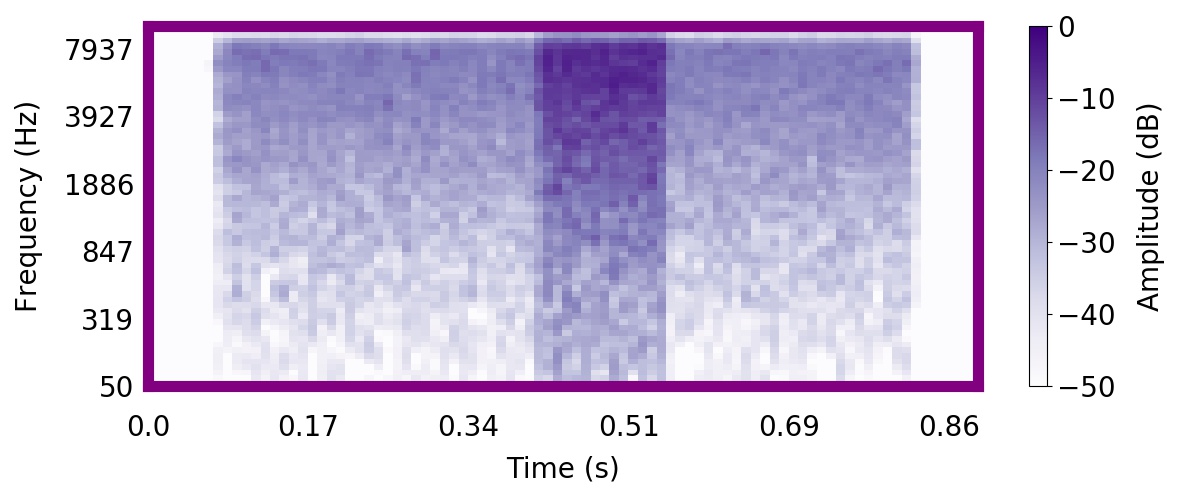
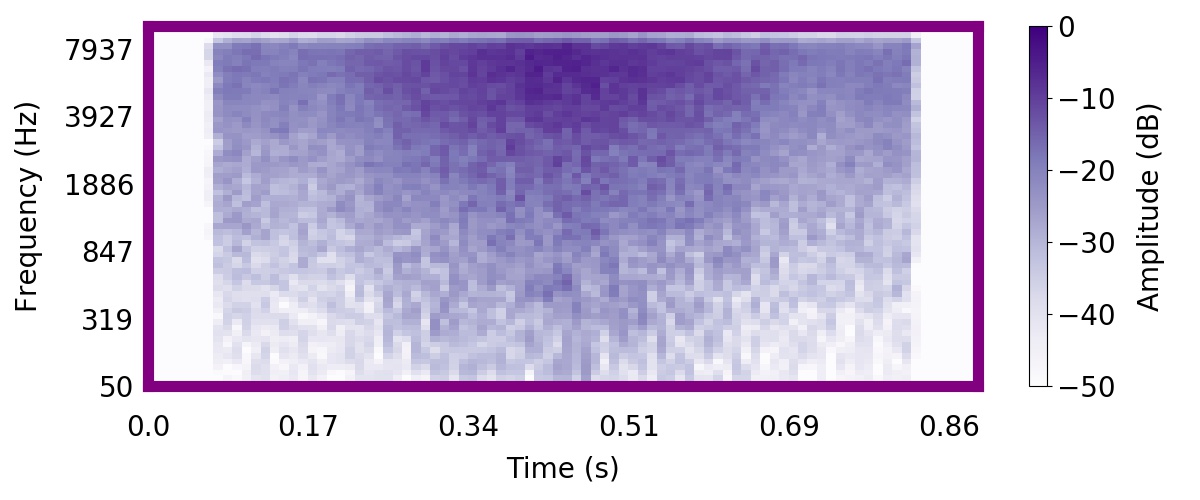
| Observation | Posterior samples of scenes | Mixture of sampled sources (if nSources > 1) | 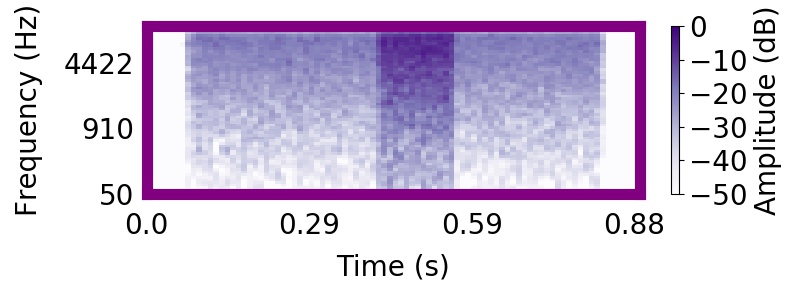 | 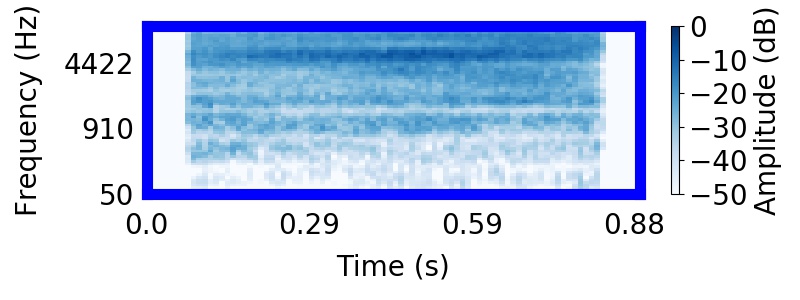
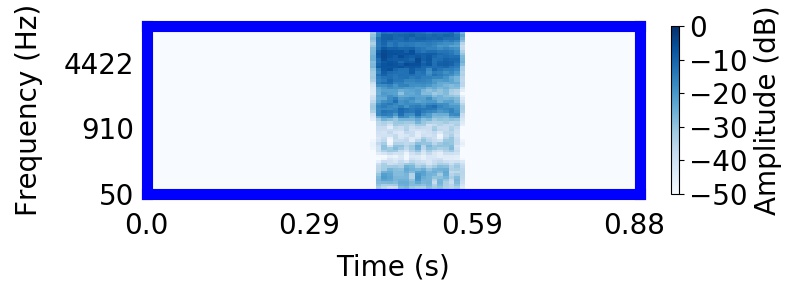 | 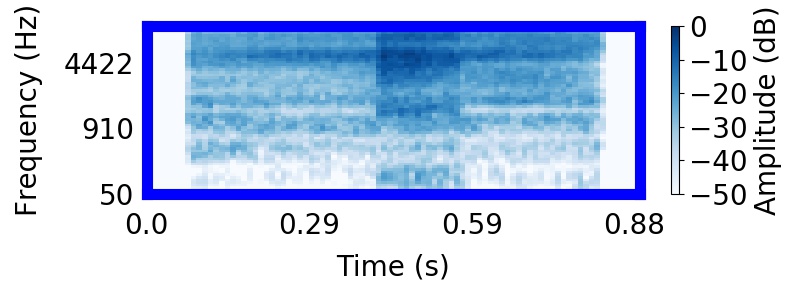 |
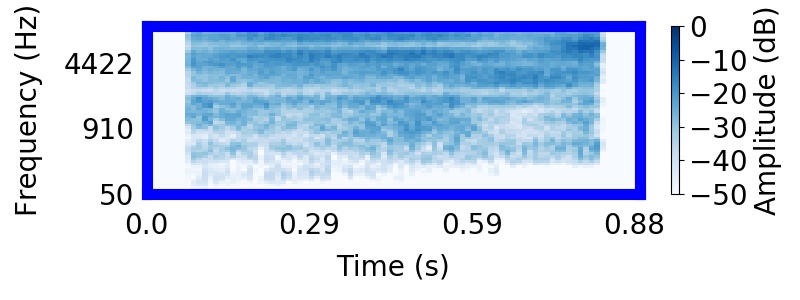
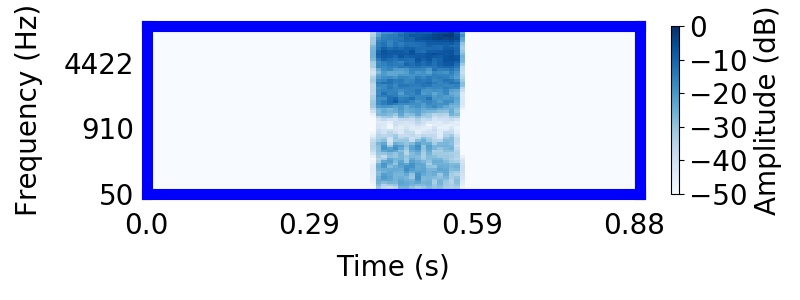 | 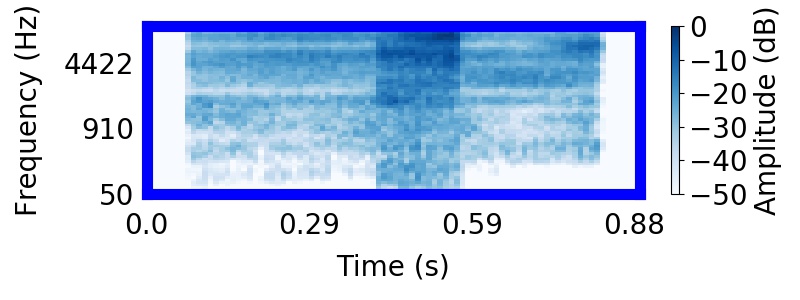 |
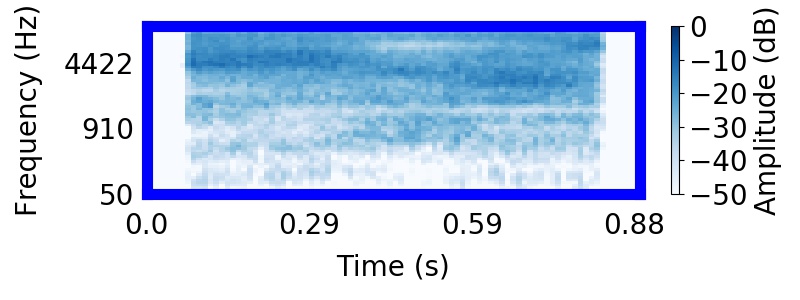
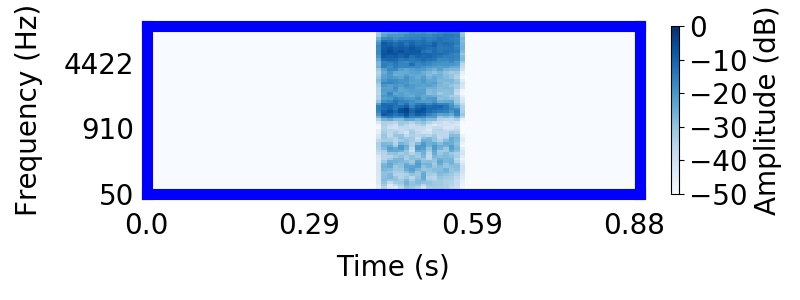 | 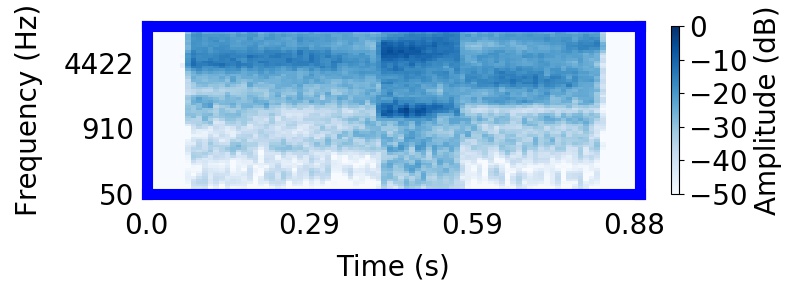 |
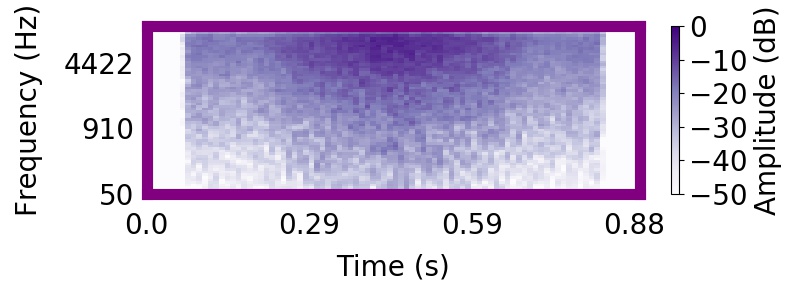 | 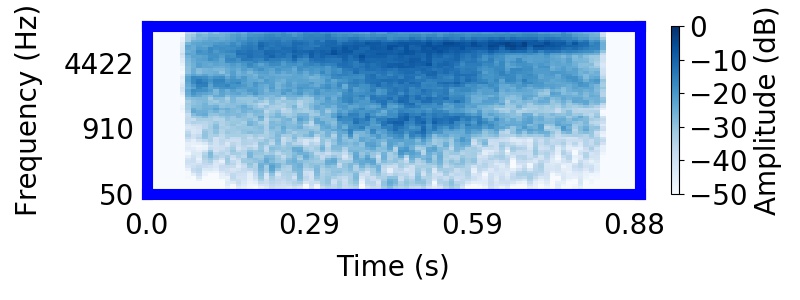 |
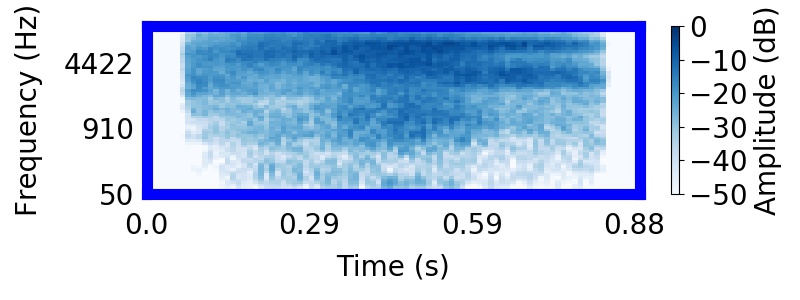 |
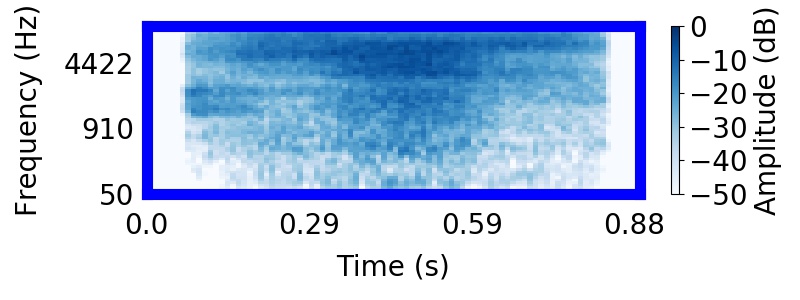 |
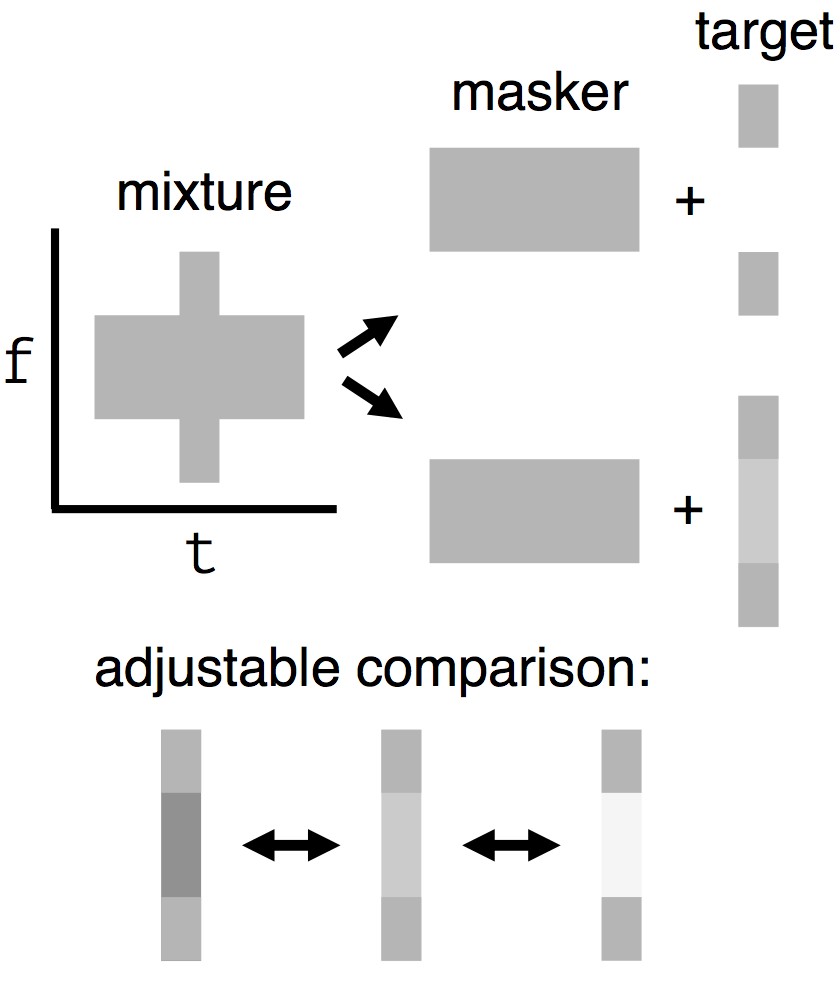
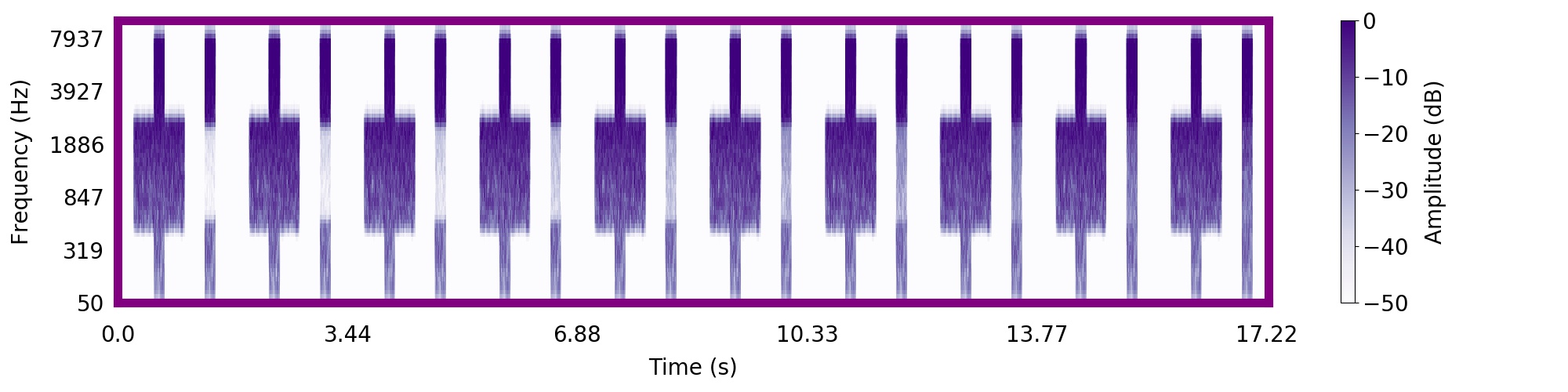
| Schematic | Observation | Posterior samples of target only |  | 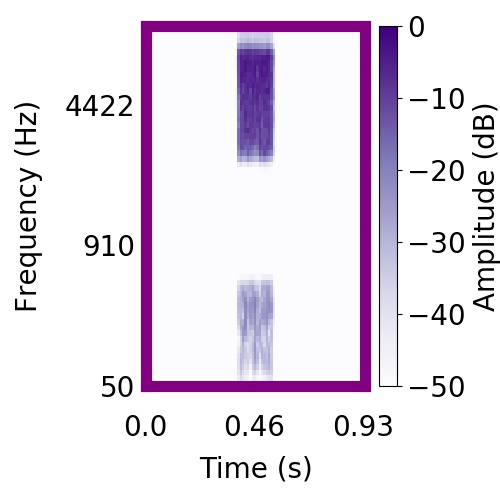 | 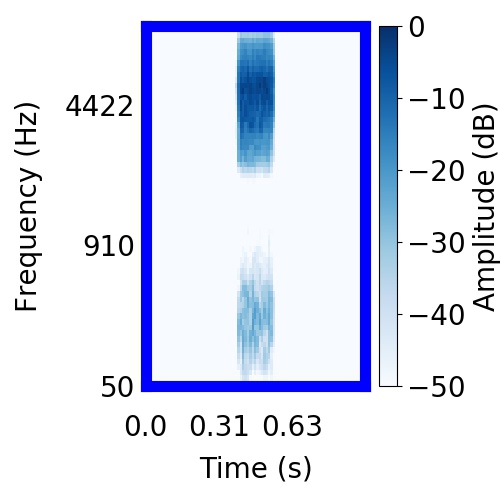 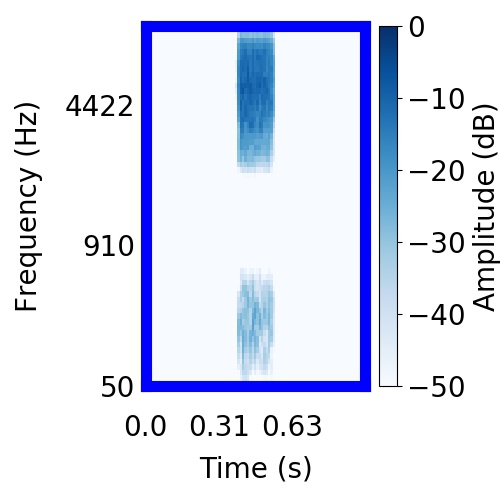 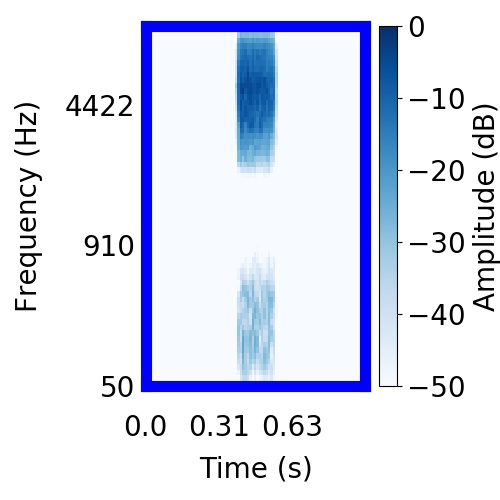 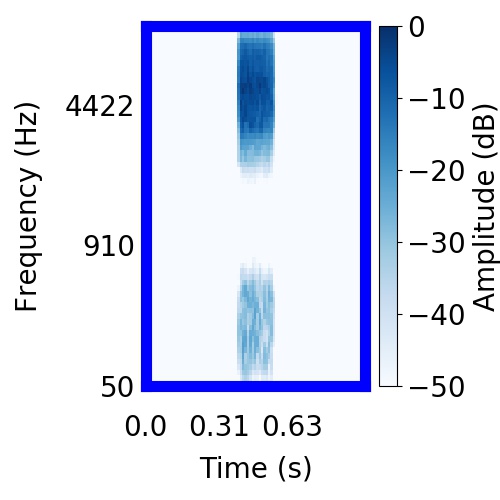 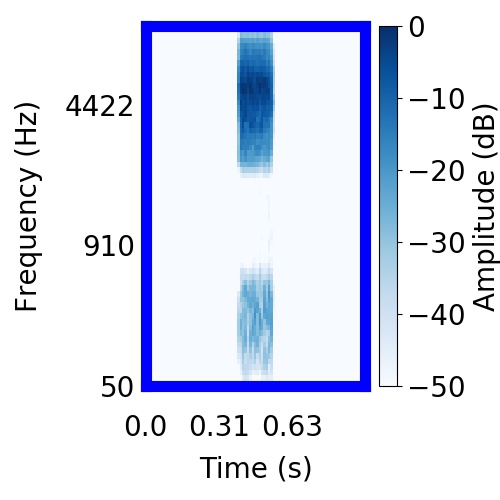 |
 | 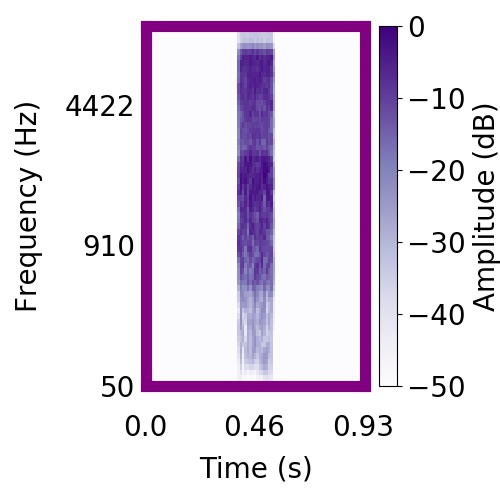 | 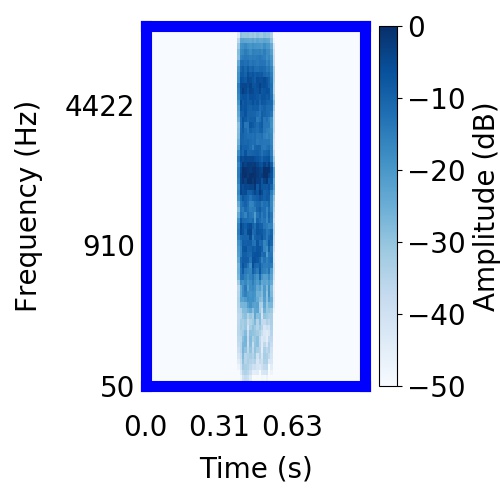 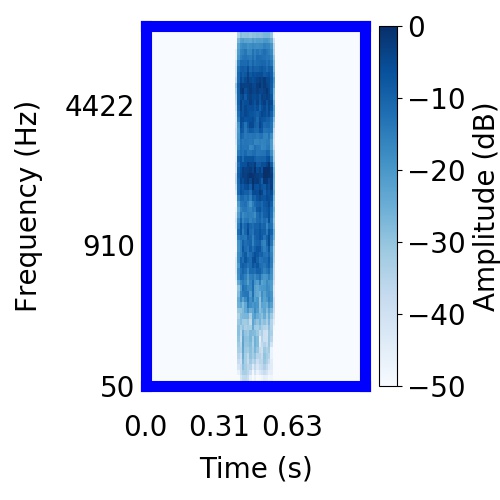 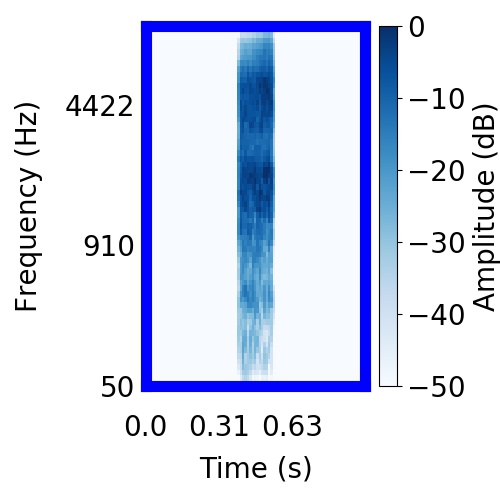 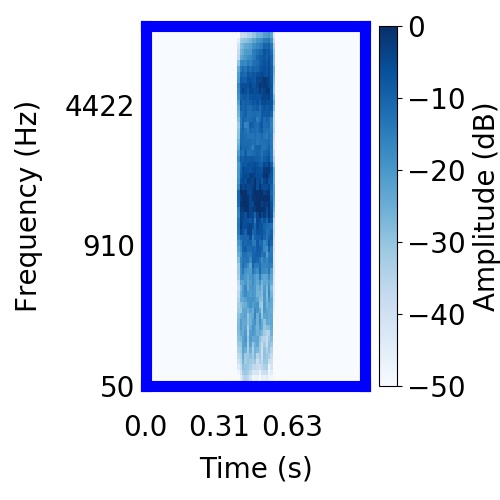 |
 | 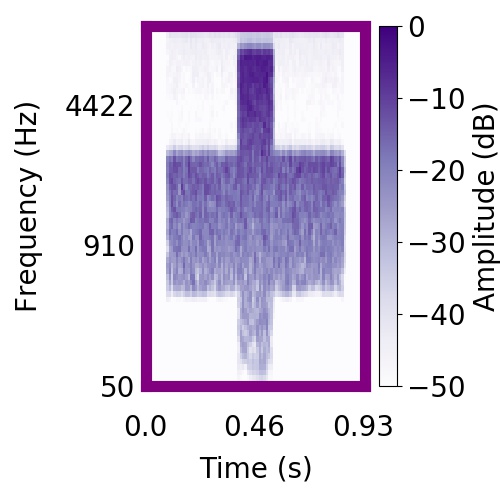 | 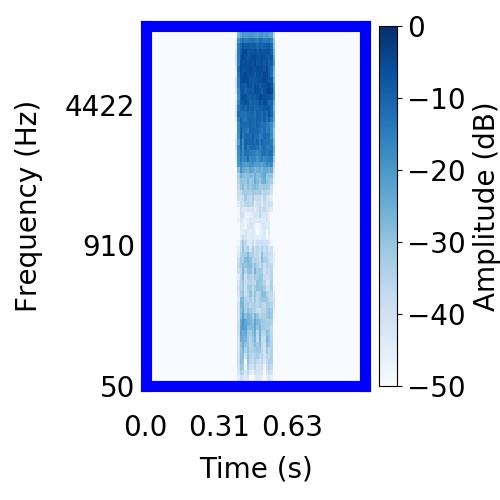 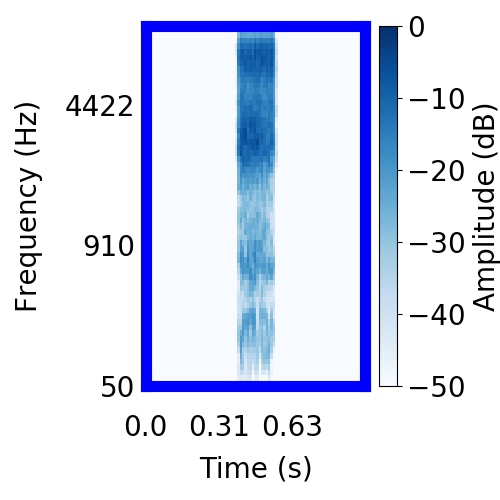 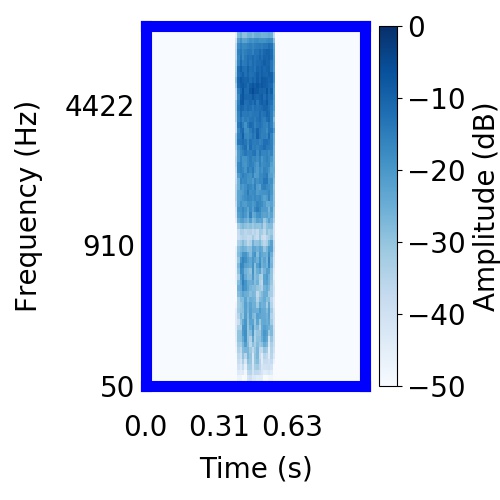 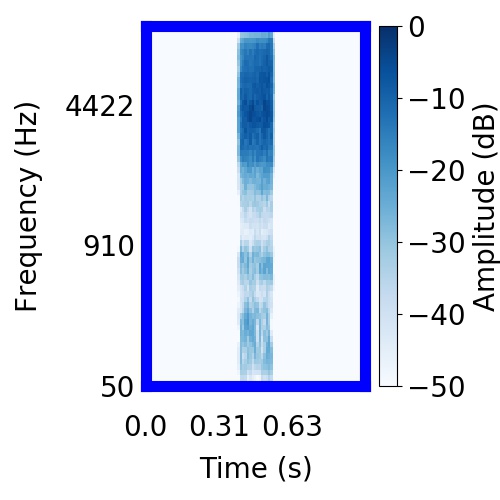 |
 | 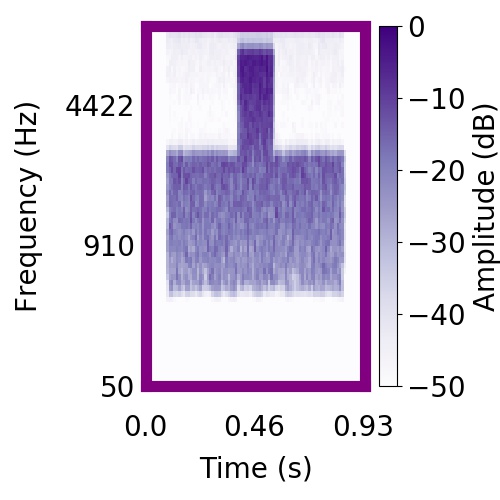 | 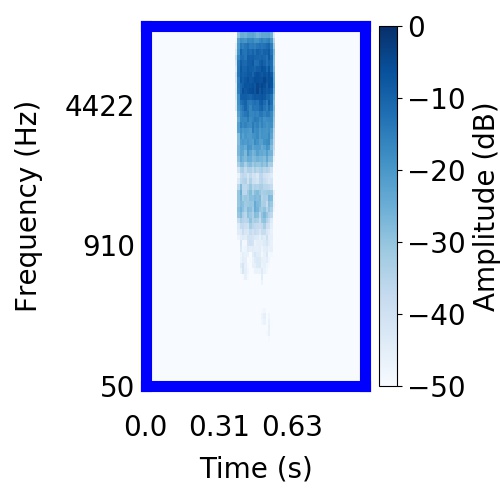 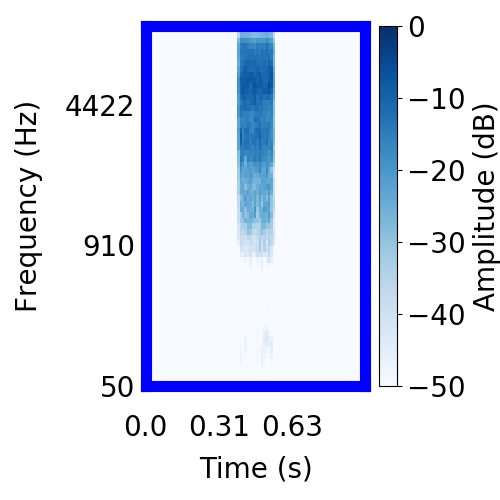 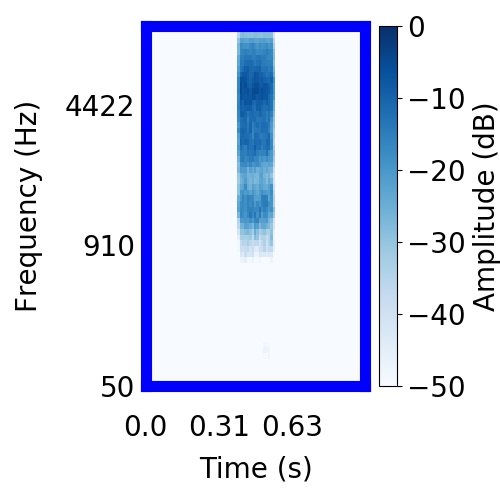 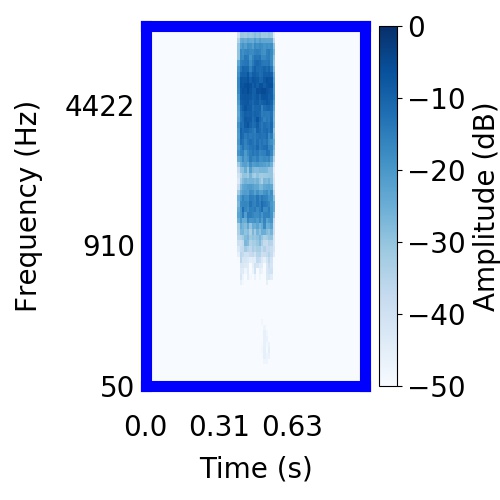 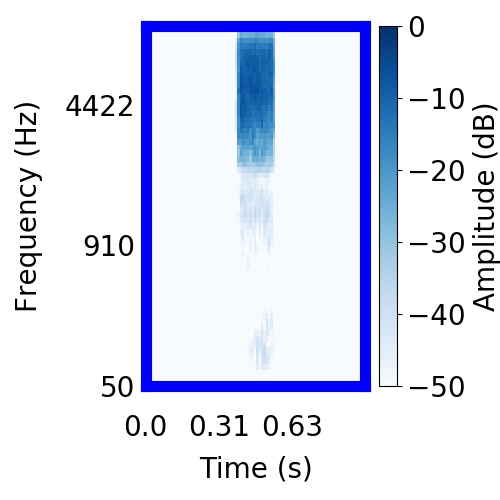 |
 | 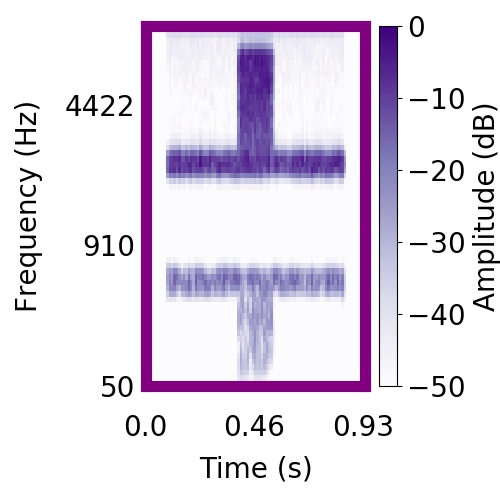 | 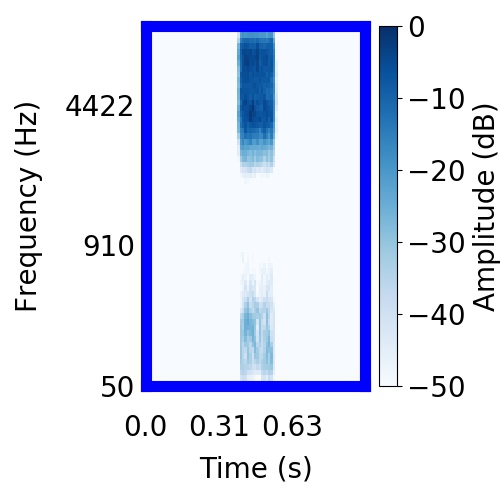 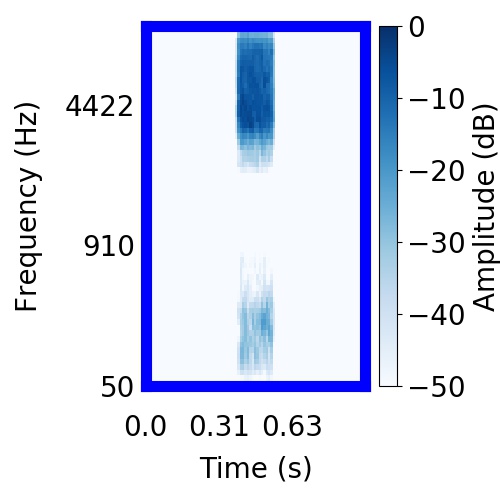 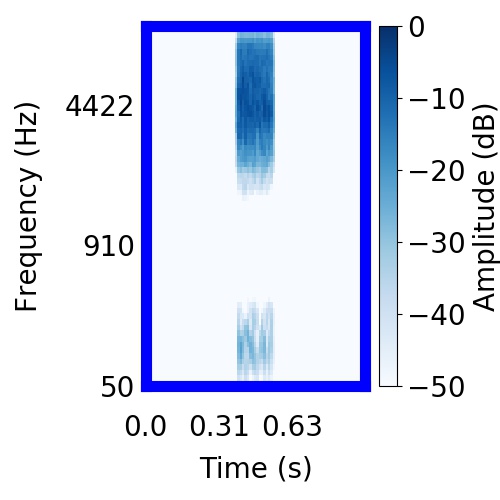 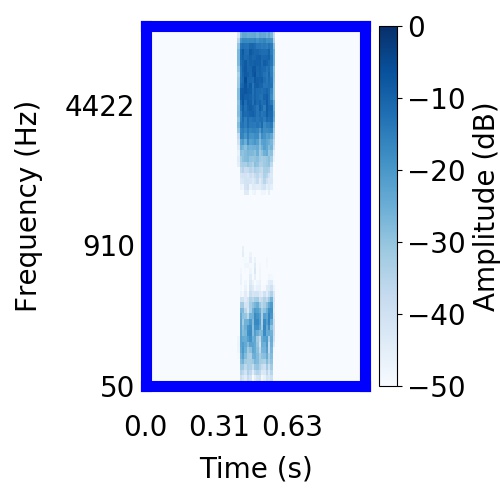 |
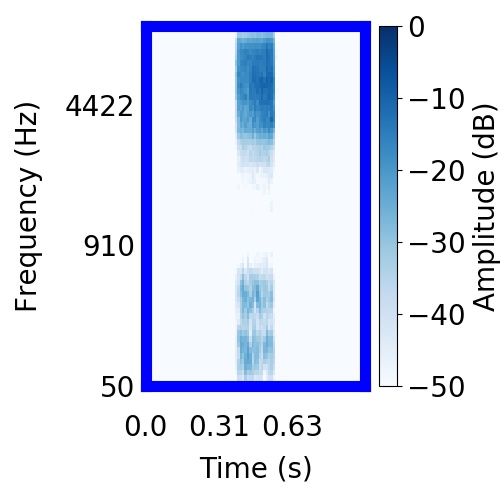
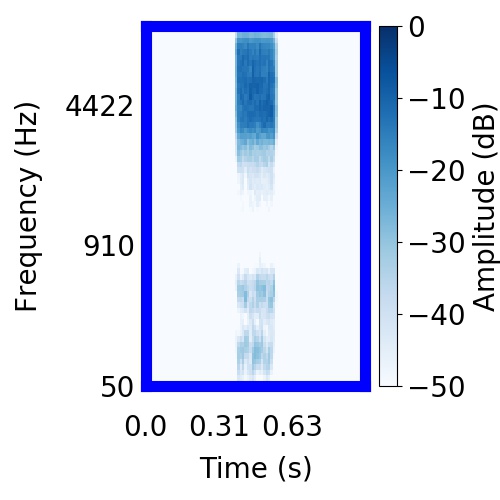
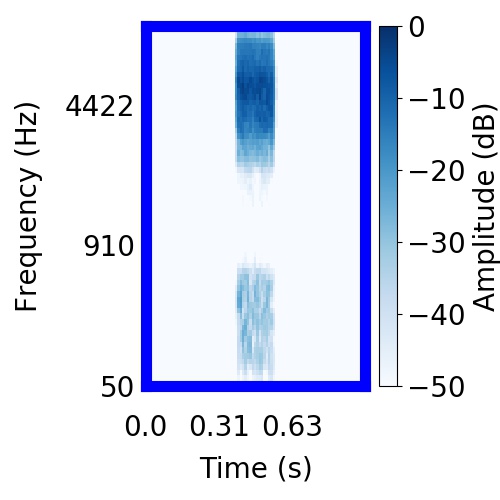
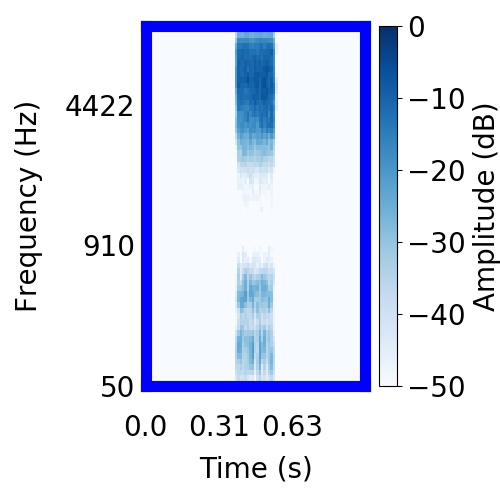
 | 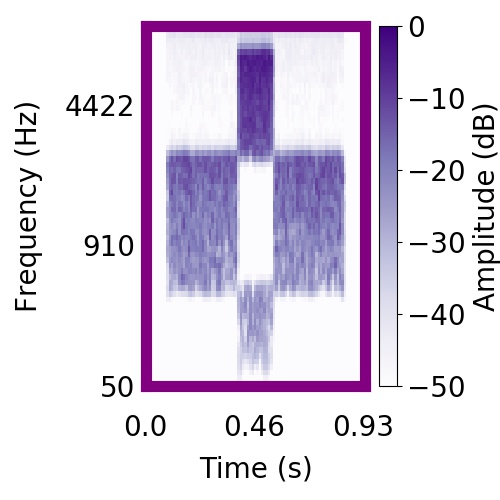 |    
|
| Schematic | Observation | Posterior samples of target |  | 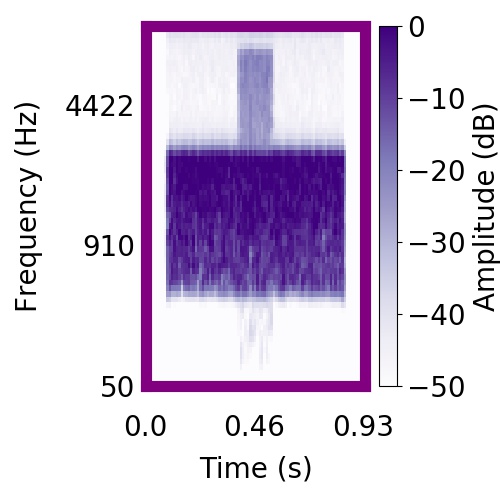 | 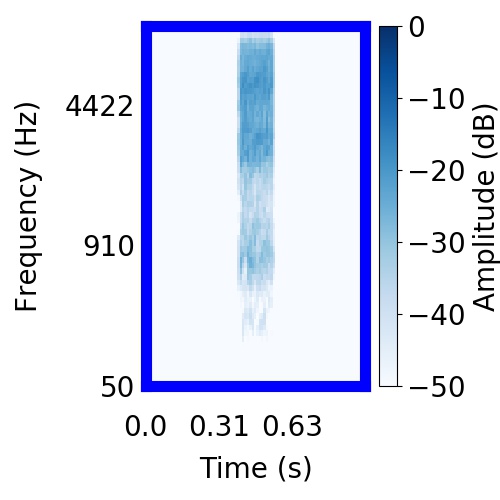 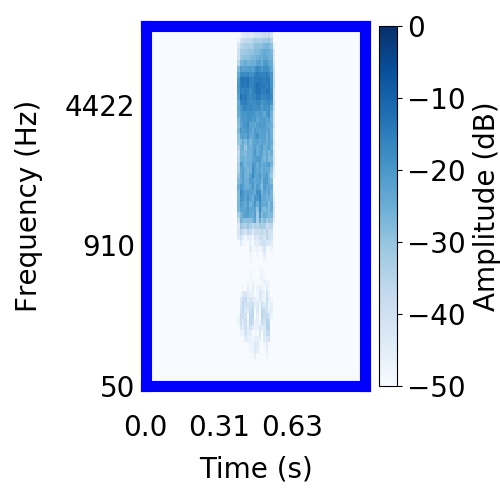 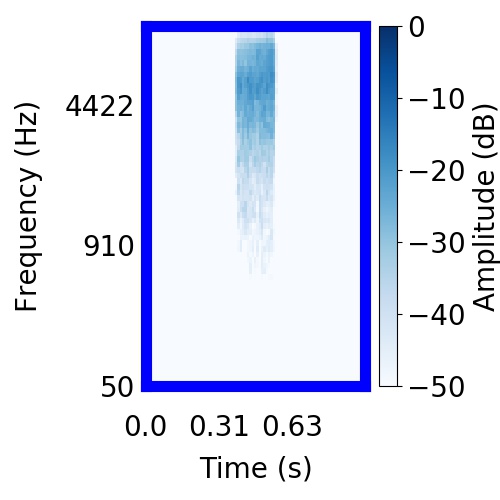 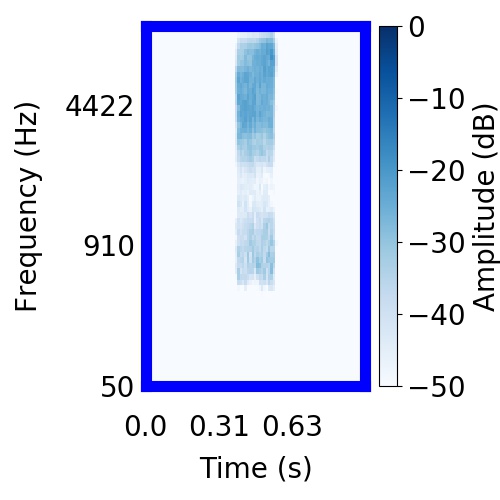 |
 | 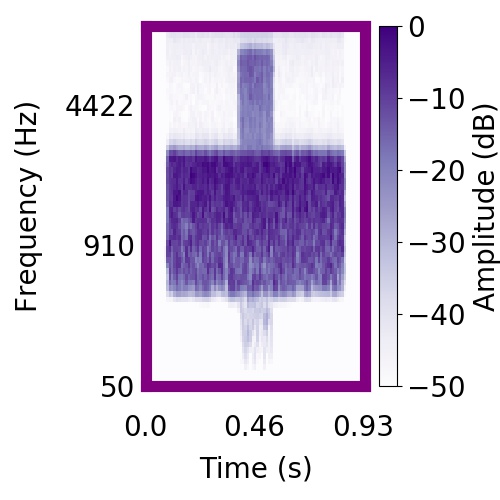 | 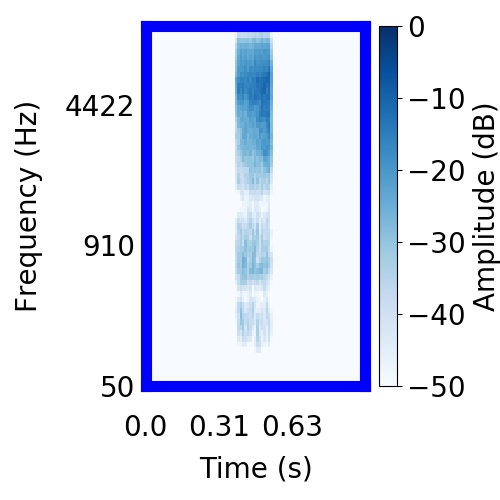 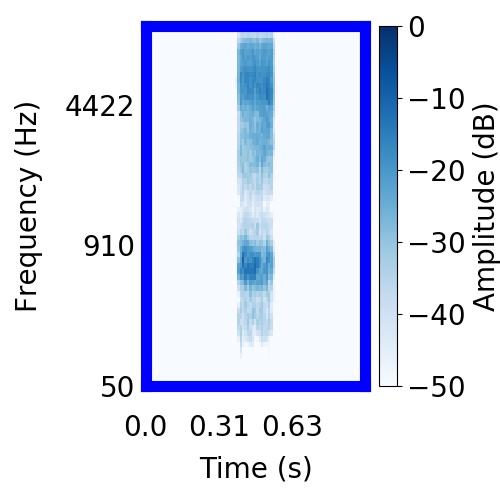 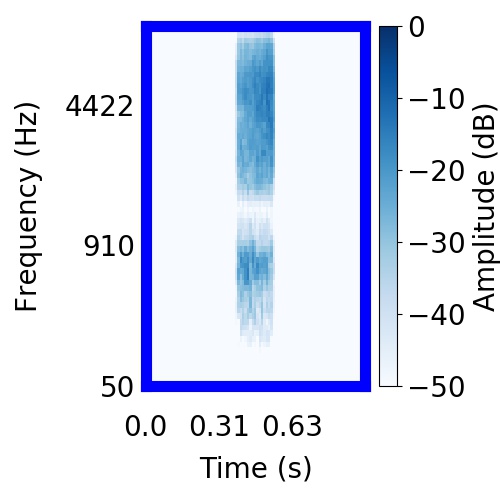 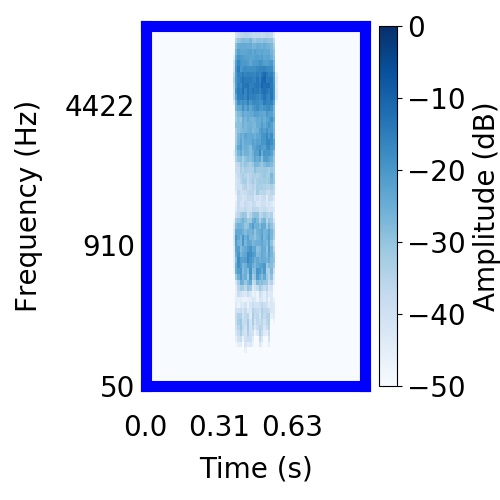 |
 | 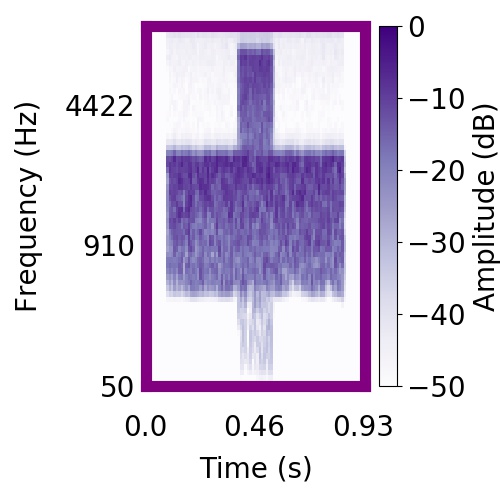 | 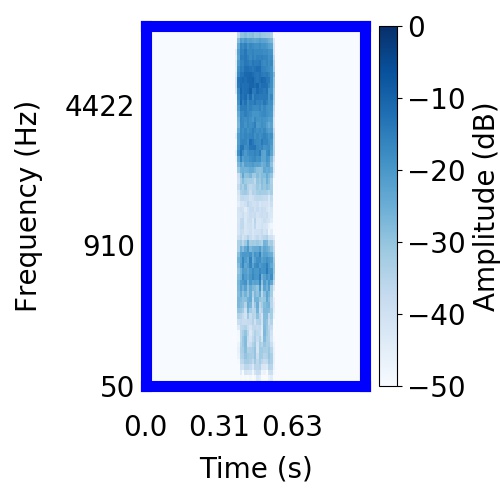 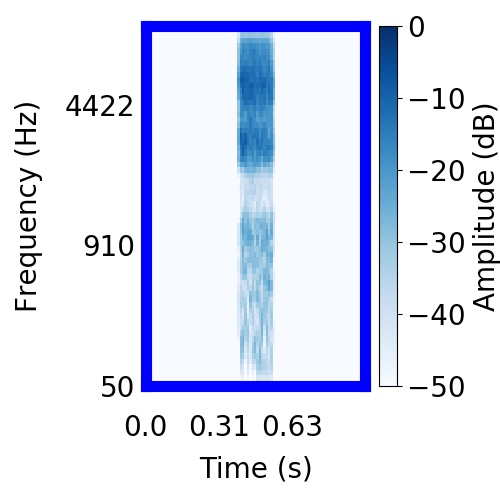 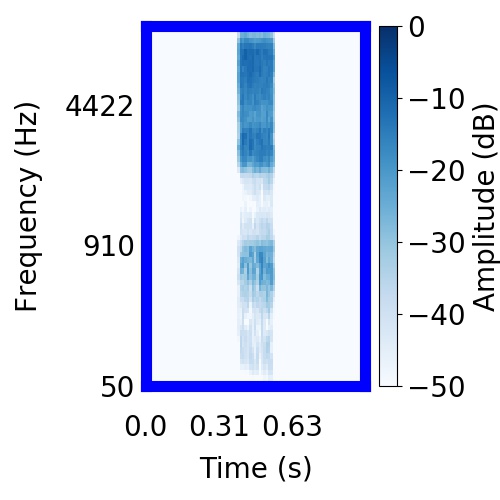 |
 | 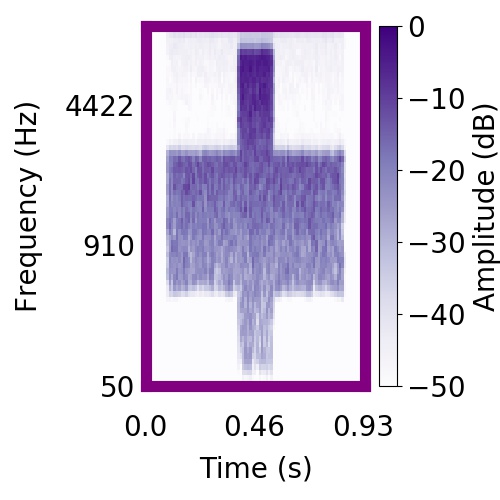 | 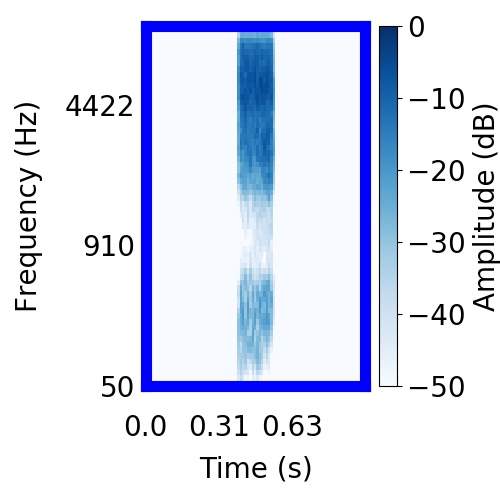 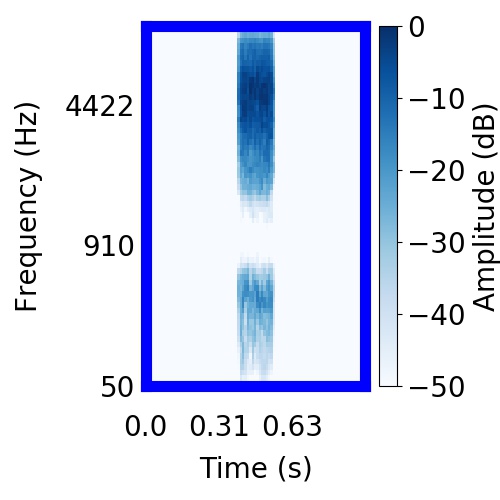 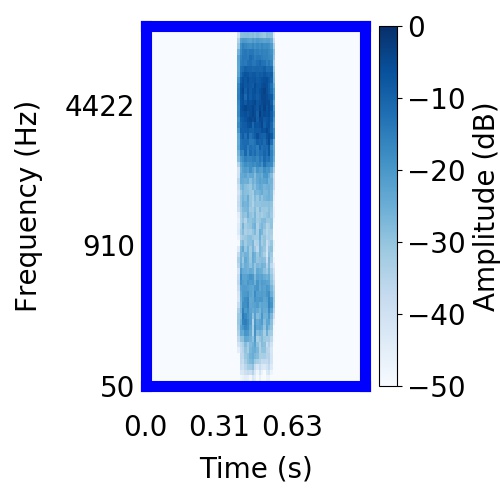 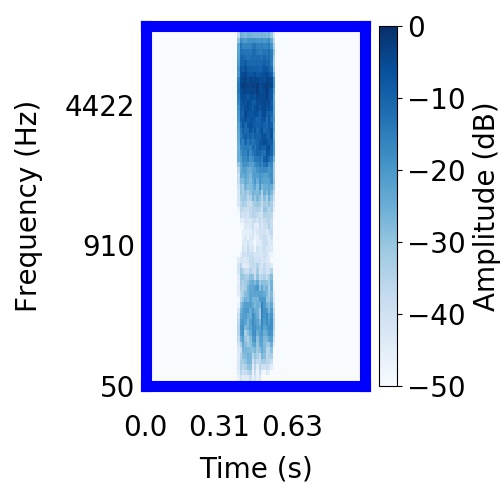 |
 | 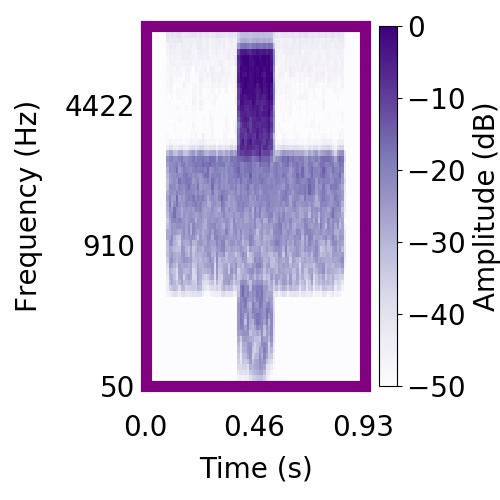 | 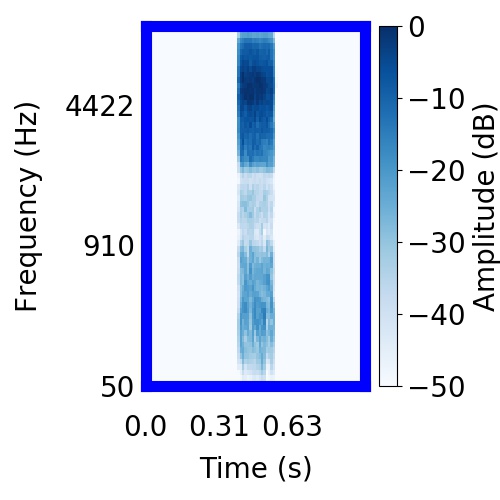 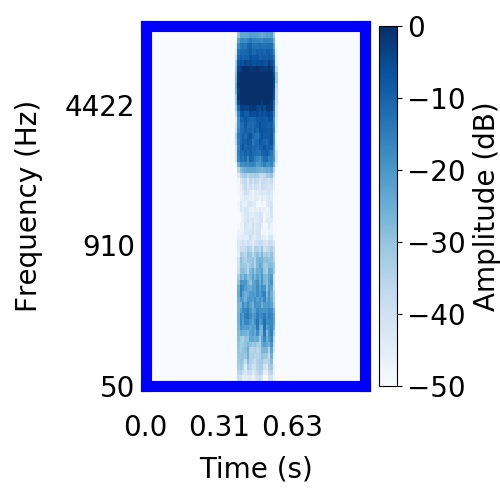 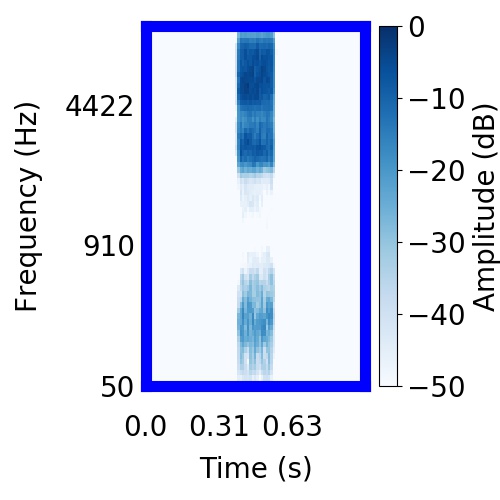 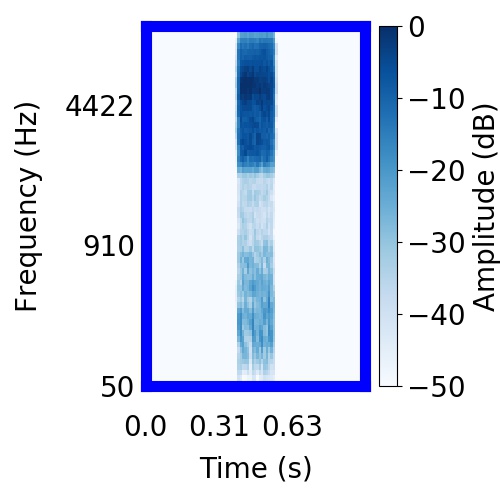 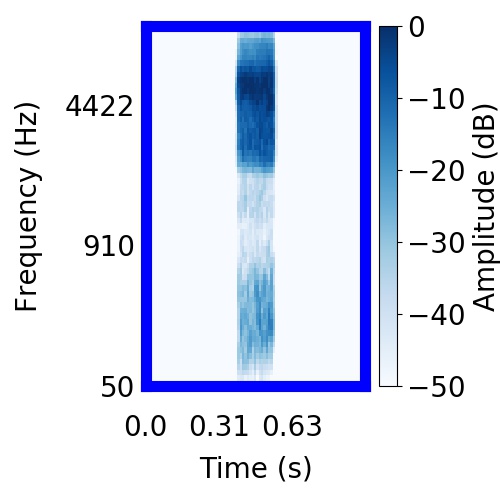 |
 | 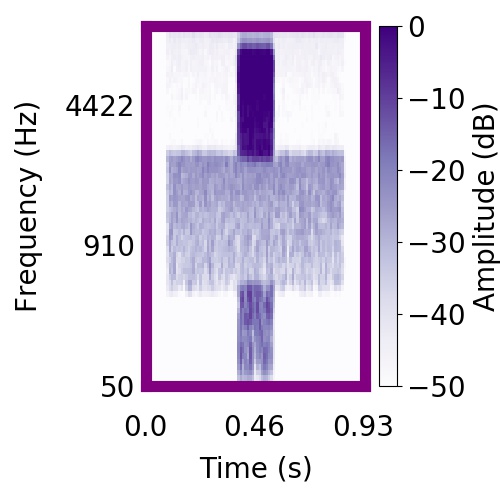 | 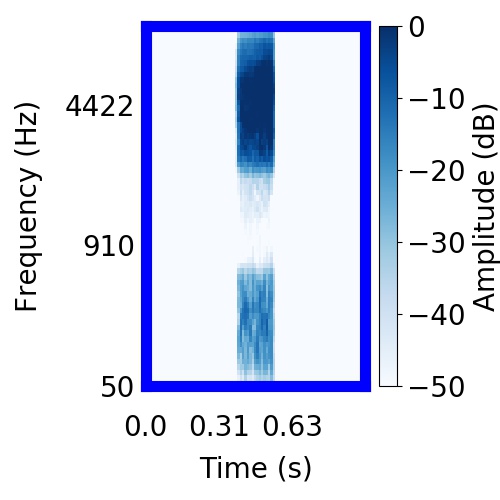 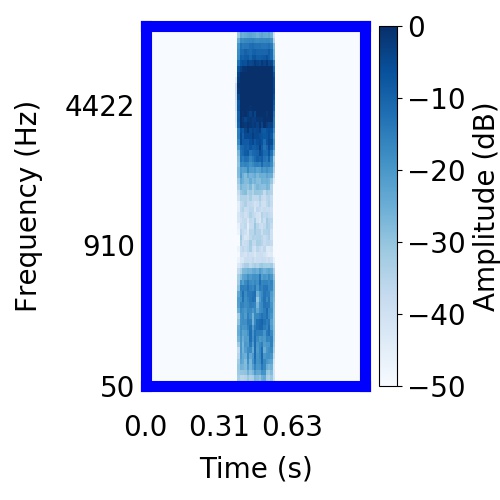 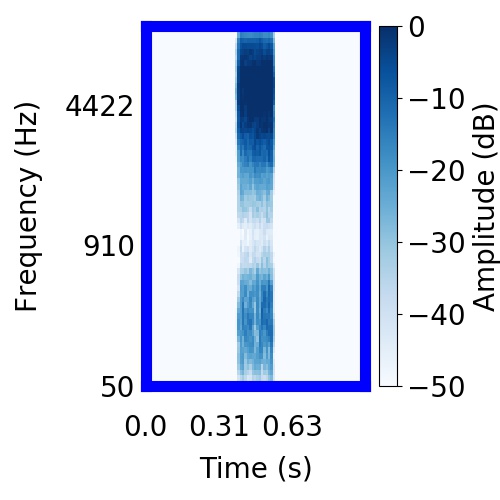 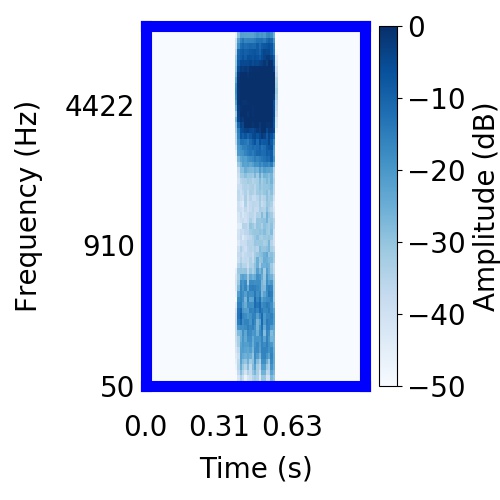 |