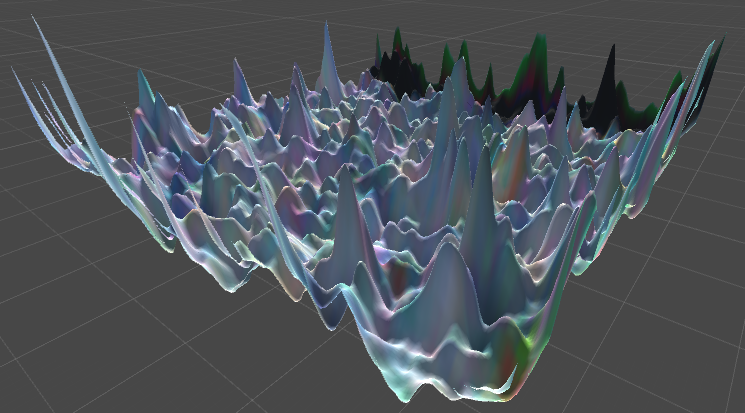
For our 6.S198 final project, we generated 3D worlds with neural networks in TensorFlow. They can be
explored online
and
viewed on YouTube. If you’re interested in learning about how they were generated, read on!
What is Procedural Generation?
Procedural generation is two big words for one simple thing: the creation of data by computers. Procedural
generation is usually used to create content for video games or animated movies, such as landscapes, 3D objects,
character designs, animations, or non-player character dialogue. One famous example of this is the planets generated
in “
No Man’s Sky.” In this game, players can explore
18 quintillion (18,000,000,000,000,000,000) unique planets and moons, which were generated algorithmically
by computers.
The amazing thing about procedural generation is that infinite unique possibilities can be created with little work from
humans. (Well, on second thought, maybe not little work from humans, but at least a “small amount” in comparison
to the infinite number of possible generations.) We decided to use procedural generation - specifically
deep learning procedural generation - to create 3D worlds of our own.
Data Collection
Why do we need data?
Input data needs to be collected before implementing
deep neural networks.
Neural networks are computer programs that greedily soak up data and learn through what we like to call
“osmosis.” In reality, the learning process consists of continually updating small numbers called
weights and
biases that allow the network to generate data, such as images or likelihood values (e.g., the likelihood
that an image is a cat).
To generate 3D worlds, we needed 3D model data and colour data. We collected terrain height maps for the 3D part of the project,
and satellite images for the colour part of the project.
An example height map from
Terrain.Party. This is a top view of a mountain range. The darker portions are lower altitude, and the
lighter portions are higher altitude.
An example satellite image from
USGS. This is a top view of the Dasht-e Lut Desert.
Terrain Maps and Web Scraping
To obtain the terrain map data, we scraped
Terrain.Party. When we first found this website, we thought, “Perfect! We’ve got a dataset and we’ve barely
even started!” It turns out that
web scraping (getting large amounts of data from the web) is not that easy. We got help from one of
our master-web-scraper friends, Bret Nestor, who wrote
code using FireFox webdriver libraries
to download and extract height maps. After many hours of scraping, we got over 10,000 height map images. Unfortunately though,
not all of the images were usable, so we needed to
clean the data, as described in the next section.
Cleaning Terrain Data
After obtaining the height maps, we noticed that some of them were duplicates, had little variation in depth (e.g., they
were almost completely grey images), or were very dark. Thus, we wrote a script
(delDarkUnvariedIdentical.py) to delete the unnecessary images and
“clean” the data. Finally, to decrease our network’s training time, we re-sized the images to 256x256px
(scaleToWidthxWidth.py).
Terrain images with good variation in height.
Before we could use the images as input for our neural network, we needed to flatten (or
“pickle”) them. Our final “pickling” script
(prepDataset.py) also rotates and flips the images to increase the total amount of training data. Rotation
and flipping also
reduces bias in the dataset to ensure the network doesn’t generate terrains that are purely in a certain
direction.
Style Image Data Collection
Style images were obtained through
USGS’s Earth as Art site. These images were very large (over 7000px in both height and width), so we ended
up resizing them to about 512px, and finally to 256px. Although the images lose detail when scaled, we figured
the images contained enough information for our style transfer network to learn.
Style images.
Height Map Generation
Generative Adversarial Network
To generate our own height maps, we used a
Generative Adversarial Network (GAN). GANs consist of a
generator network, which generates fake images, and a
discriminator network, which discriminates between real images and fake images. This generator-discriminator
pair has been compared to a counterfeiter and the police. The counterfeiter (generator) creates increasingly
realistic fake bills, and the police (discriminator) become increasingly good at discriminating between real
and fake money. Essentially, as the police learn to find the fake bills, the counterfeiter needs to create better-looking
bills, resulting in hyper-realistic bills in the long run. GANs work the same way. As the discriminator learns
to spot fake images, the generator learns to create more realistic images.
The discriminator network discriminates between real and fake images. The generator generates fake images.
Amazon Web Services
It turns out that running a GAN (and almost any deep neural network, for that matter) takes an immense amount of computing
power. Thus, we ran our GAN using TensorFlow on one of
Amazon Web Services’ p2.xlarge GPUs.
Network Configuration, Iterations, and Hyperparameters
In practice, GANs are quite finicky and require a lot of tweaking before they generate realistic images. We uploaded
thirteen different versions of our GAN to Github, so that you can see our network’s progression. We also
listed the modifications we made in the
README. Each GAN has different attributes and benefits, and produces very different height maps. Note that
the final version of the GAN
(v10) can be trained for much longer than the other GANs, as it resets the training data once the GAN has
already been fed each training image.
Other tweaks include changing the discriminator and generator’s
learning rates,
number of layers,
type of layers, convolutional
filter sizes, and image
batch size. Our final network had the following
hyperparameters (learning rates, filter size, batch size, etc.) and layer configuration:
Batch Size: 150
Optimizer: Adam Optimization Algorithm
Discriminator:
Learning rate: 3e-6
Convolutional layer filter size: 5x5px
Four convolutional layers with Leaky ReLU activation functions
Generator:
Learning rate: 3e-4
Convolutional layer filter size: 8x8px
Three convolutional, image upscaling layers with Leaky ReLU activation functions
The generator takes input images (left), passes them through a network, and produces output images (right).
Colouring the Height Maps with Style Transfer
Fast Style Transfer
Fast style transfer refers to the concept of taking two images - a content image and a style image - and combining the features
to produce an output image with the content of one image and the style of another. It does this by generating
a loss to both a style and content image and creating an output image that tries to minimize this loss. It uses
a
gram matrix, which is a matrix that is multiplied with the transpose of itself, to find the style of the image and compare
it with the original. Getting the distance between this matrix and the original style gram matrix gives us the
style loss. A similar procedure can be done to find
content loss. The model calculates the total loss by summing these two values. Our style transfer network
uses
VGG19, which is a 19-layer neural network, to identify both style and content of a picture, among many other
features.
Example style transfer through
Deepart.io. The style image is on the left, content image in center, and the final result is on the right.
Note the similarities between the final image to both content and style images.
To illustrate, in the image above, we first note the image on the far left. This is our style image, which means it has the
aesthetic qualities and colours that we’d want for our final output. The image in the middle is our content image,
which refers to the details of the image. We want to create an output that has the information of the content
image, in this case, a height map, with the artistic style of our style image. The resulting image is on the
far right, which was produced by Deepart.io. We see that it has the distinguished patterns and colours of the
style image while also preserving the blotches of white and black on our content image. Using a similar approach,
we hoped to generate stylized height maps to give our 3D models colour.
Setting up the Fast Style Transfer Network
The code we started from was Logan Engstrom’s
Fast Style Transfer code. We initially ran his code on
Google Colab, feeding it a 512x512px input style image and 512x512px input content images. However, we noticed
that we were running out of memory before the program could even begin training. After a few iterations of testing,
we found that using 128px square images were compatible with both the code and Google Colab.
Training the Fast Style Transfer Network
We began with small batch sizes and small epochs when training the model to see the preliminary results, however, we noticed
that even with a smaller dataset and a GPU, the training was taking close to the 12 hour maximum limit on Google
Colab. We then decided to implement a way to save the model and reload it so that we could continue training.
This allowed us to get better results. After increasing the amount of training data, the batch size, and the
number of epochs that the model was trained for, the model began to have less loss in both style and content.
We also changed the weights of the style and content images, which means that we altered how much each image
should contribute to the model, and began to see more defined and promising images.
Left: low epochs, less training data. Right: high epochs, more training data.
Unfortunately, one of the big problems with the training data was that we didn’t have enough of it. We initially planned
on having 56 thousand images for training the style and content losses through, but Google Drive wouldn’t allow
us to import these 56 thousand images. Instead, we ended up importing only 28 thousand images and training on
these. From previous assignments, we knew that using a larger sample of training data will tended to result in
more accurate models, but unfortunately, we were not able to expand the training dataset. In the future, we think
increasing the training samples and increasing training time would result in a more accurate representation of
the style and content images. Even with the resources that were available, we were able to see the initial results
that the model had learned.
Challenges
Checkerboard Artefacts
We started to notice a consistent grid-like structure appearing in our generated results for both the GAN and style transfer
networks.
A generated image with a grid-like structure.
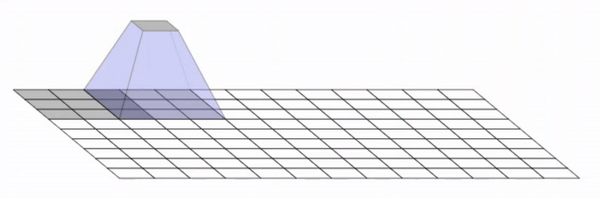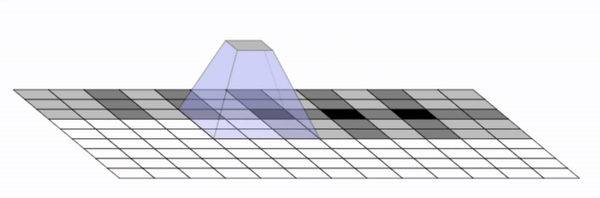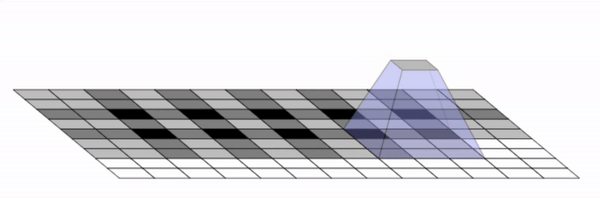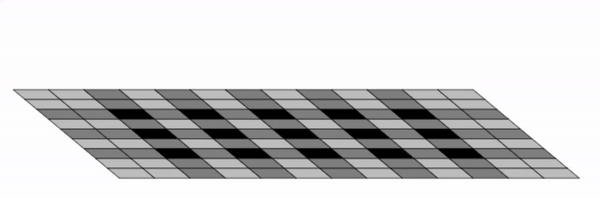
We found that these checkerboard patterns were caused by overlapping kernels and strides. More specifically, this occurs
when the kernel size, which is the output size of the filters, is not divisible by the stride size, which is
the amount that each filter is translated by. Below is a diagram that illustrates the overlap in kernels that
create this grid.
We solved this issue by using image_resize with bilinear sampling instead of using convolutional transpose. This means that
we increase the size of the image by adding pixels that use the pixels on either side to determine its value
rather than creating kernels and strides to resize the image. This gave us much better results and removed the
artifacts from our images.
Example output results from both the GAN and Fast Style Transfer using
bilinear sampling.
Visualizing the 3D Worlds
Making Explorable Terrain
To create an initial 3D model prototype from a height map, we used a
Java program that converted PNG files to STL files. The following image shows a height map of Kelowna, BC,
Canada, and the resulting 3D model.
A coloured 3D model of Kelowna. The deep blue and red part of the model is
Okanagan Lake.
To add colour to the 3D model, we “stamped” a style-transferred image of Kelowna onto the 3D model. You can see the stylized
image below. It was generated using the content of the height map above, the style of Leonid Afremov’s “Rain
Princess” painting, and
Fast Style Transfer.
The stylized image of Kelowna.
Being able to view the height map in 3D was exciting, but we wanted to go one step further and create
explorable 3D worlds. To do so, we converted the
PNGs to RAW files using GIMP, and imported these files into a program called Unity as terrains. The final
results are shown below.
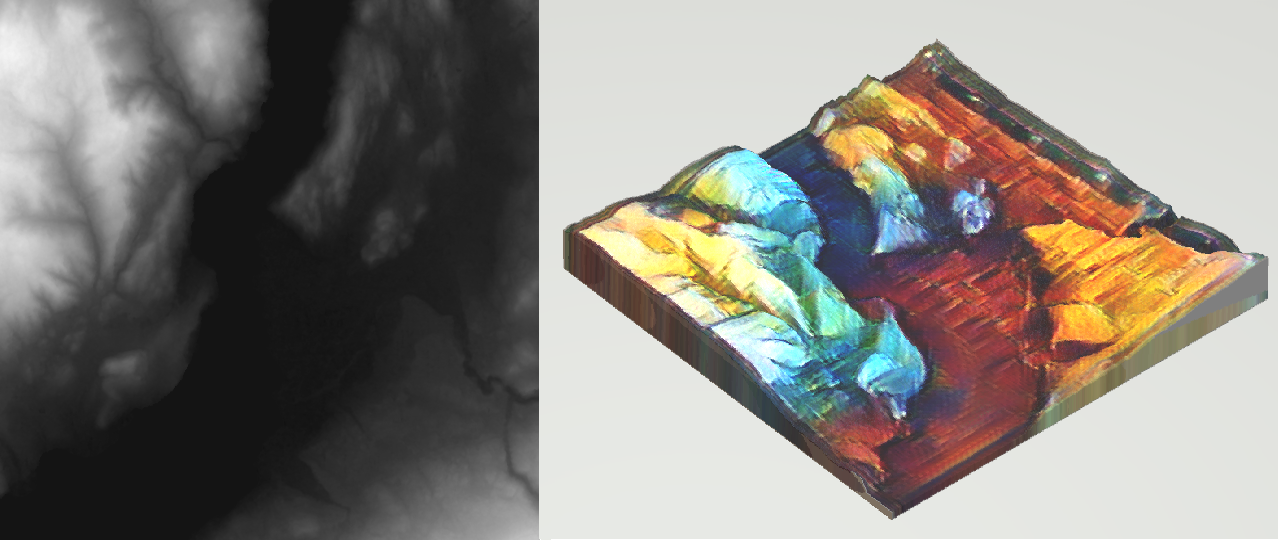
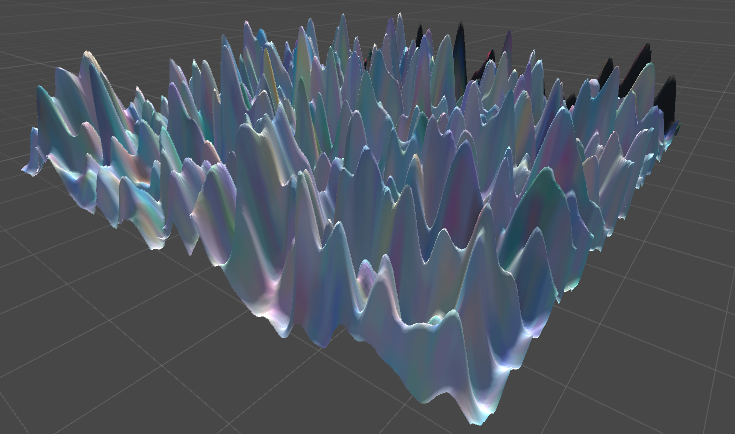
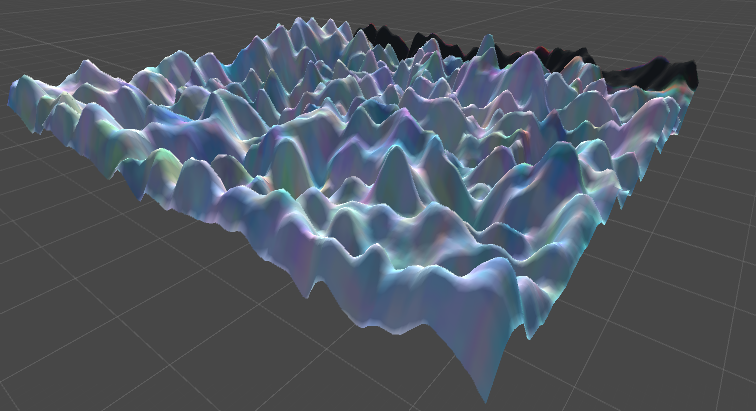
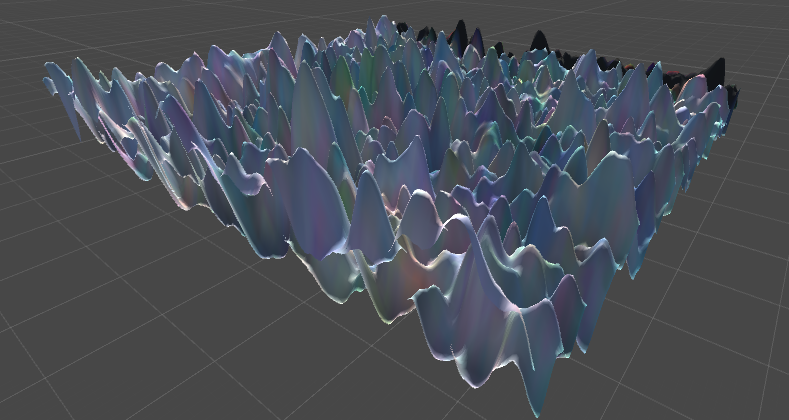
A 3D world we called, “Rolling” due to its rolling hills.
A 3D world we called, “Peaked” due to its many peaks.
A 3D world we called, “Small Hills” due to its bumpy terrain. This terrain is also shown at the beginning of this article
with a different style image.
A 3D world we called, “Varied” due to its large variation in height.
A 3D world we called, “Ravines” due to its small crevices or ravines.
A 3D world we called, “Artefacts.” This model was generated with a height map and stylized image that had checkerboard artefacts.
Because seeing something virtually just isn’t enough
Finally, to allow ants and other small critters the pleasure of exploring our virtual worlds (because this is
clearly a necessity), we 3D printed a few of the generated landscapes.
“Artefacts” in 3D printed plastic.
“Ravines” miniature.
“Rolling” in all of its 3D, hilly glory.
Final Notes
All in all, through this project we learned that creating an accurate deep learning model takes a long time, a lot of resources,
and a lot of planning. Luckily, we had awesome mentors and online resources to help us, and we were ultimately
successful in creating interesting, unique terrains. Many thanks go to our Google mentors, Lauren Stephens and
James Wexler, our 6.S198 LA, Efraim Helman, the 6.S198 instructors, Natalie Lao and Hal Abelson, and the rest
of the 6.S198 crew! Couldn’t have done it without you.
 An example height map from
Terrain.Party. This is a top view of a mountain range. The darker portions are lower altitude, and the
lighter portions are higher altitude.
An example height map from
Terrain.Party. This is a top view of a mountain range. The darker portions are lower altitude, and the
lighter portions are higher altitude.
 An example satellite image from
USGS. This is a top view of the Dasht-e Lut Desert.
An example satellite image from
USGS. This is a top view of the Dasht-e Lut Desert.