Elliot Schwartz
6.033 Design Project #1
Engler TR11
March 20, 1997
Partly read-only portable web sites are useful when the maintainer and browsers of a web site do not always have access to the Internet, yet wish to keep up-to-date on any changes in content. A transparent, platform-independent design for a such a site is presented. The design involves modifying the web pages and server, and makes use of the HTTP Redirection and Client-Pull forwarding techniques. Because modifications to web browsers and operating systems are not required, this design can be implemented quickly and cost effectively.
As the World Wide Web enters mainstream technology, more and more information begins to exist on the web in its primary or only form. Web publishing allows up-to-date information to go from producers to consumers very quickly, and users have begun to expect this type of service. However, access to the Internet is not universally available. Wide spread portable computing and a lack of mobile networking infrastructure means most laptop users do not have a fast, reliable connection to the Internet while travelling. This is especially true in parts of the world where the Internet infrastructure is not suitable for useful web browsing. Because of this non-universality, it is desirable to access and update web pages "off-line," when access to the Internet is not an option.
The storage technology necessary to accomplish this exists. Recently CD-ROM technology has become very available: most new desktop computers are equipped with CD-ROM drives; high end laptops often have a CD-ROM option; and, CD-ROM writers are relatively inexpensive. The large data capacity of a CD-ROM (650 Mb) makes it ideal for storing collections of web pages. The small, lightweight, and durable disks are well suited to laptop use. Low manufacturing costs mean that the disks are cheap enough to give away, thus CDs provide an ideal medium for off-line read-only access to a web site. Hard drive storage is large and inexpensive as well; new computers typically have one to two Gigabytes of storage. A hard drive of this size can hold even a large web site and allow the maintainer to edit pages.
Using these technologies, it is possible to implement a system that allows web pages to be copied to CD and accessed off-line. However, it is also important that users get the most recent information possible. CDs can only be produced periodically, and are therefore subject to going out of date quickly. Similarly, transferring information in person leads to quick obsolesence. Any system should therefore let browsers view the most up-to-date copy of a page, whether it be on a CD, the local hard drive (HD), or a remote web server. The system should also let the maintainer of the pages edit them off-line, update the web server periodically, as well as give copies of the CD-ROM and updated pages to colleagues.
Accomplishing all these tasks is difficult. The current web model doesn't support this application: URLs are designed to point at one object, in a specific location. To get the most recent copy of a page, it is necessary to have a scheme that allows pages to exist in several locations (the web server, the HD, or on CD), and to pick the most recent version available. The approach used in solving the problem is to look for a way to simulate this behaviour within the current framework of the web, allowing existing web browsers, servers, and protocols to be used without modification. Though this paper is written using an Egyptologist and his colleagues doing fieldwork as an example, the results are applicable to a wide variety of similar applications.
The following criteria must be met for the system to solve the stated problems:
The following criteria are necessary for the system to be successful:
All of the following approaches satisfy the primary criteria and solve the problems posed by the secondary criteria to varying degrees. Approaches which cannot satisfy the primary criteria include modifying only the web server (since not all clients have web access) and modifying only hardware (since the problems are coordination, not resource-related problems).
One approach is to modify the web browser so that it has the capability to determine which version of the page is most recent. This approach is appealing because the browser is the logical place to make this decision, and this ability would be useful to have in general. Most web browsers that are used today are commercial products, so changes would need to be implemented by the authors. Also, the protocols used to retrieve documents are IETF standards, and any change would need to go through the Internet Standards Process [1].
Another approach is to modify the operating system so that we can trap accesses to pages via the file system, and redirect them to the most recent page (whether via the network or elsewhere on disk). Like modifying web browsers, modifying the operating system also requires source code. It also may affect other software on the machine.
The web pages (on the CD, HD, and web server) could be changed so that a browser always gets the most recent page. This would require a change in the editing and distribution of the pages, and possibly a modification of the web server.
Modification of the Web Pages is the most viable approach. It is the
only method that provides a platform-independent solution for colleagues:
OS changes would be unique to the operating system, and browser executables
would have to be generated for every platform. If a colleague needs to
use a different web browser to use the system, he or she will surely notice
the difference, while changing the pages and server is transparent to users.
The difficulty of changing an operating system is very high, since code
is typically complicated. Also, all the machines used by colleagues would
need to be modified to change the web browser or operating system, and
changes would likely have to be performed by the company that produced
the software. In the recommended system, only the web server and the maintainer's
notebook need to be changed, and changes can be performed by a local programmer.
Table 1. Comparison of Possible Approaches.
| Approach | Platform- Independent | Invisible to user | Difficulty of Changes | Machines to Change | Change developed by | Change installed by |
| Modify Web Browser | No | No | Moderate | Many | External company | Maintainer or colleague |
| Modify Operating System | No | Maybe | Very High | Many | External company | Maintainer or colleague |
| Modify Pages and Server | Yes | Yes | Moderate | Two | Local Programmer | Local Programmer |
While all of the above approaches can satisfy the critical criteria, all but the recommended approach fail to meet most of the criteria that would be necessary for the system to actually succeed. These alternate approaches may solve the problem in principle, but if they are too difficult or expensive to deploy and use, then the problem is merely exacerbated.
This section presents a detailed design using the recommended approach. First a general overview of the design is given. Next, the background information necessary to understand the specifics of the design is provided. After this, the format of the web pages is discussed, followed by an example of browser operation. Finally, modifications to the web server and procedures for editing pages and updating the server are described.
Under this design, the maintainer's laptop is the ultimate repository for current data. He or she can edit the pages in this repository with the help of tools that maintain the necessary web page formats. Additional tools generate snapshots for placement on CD or update the web server. The data in the repository can be used by unmodified web browsers to view the most recent copy of any page.
Through an introductory configuration page, the user selects whether an Internet connection is available or not. If the user does not have a connection, selecting a link will cause the browser to load the corresponding page from the HD. However, if the page hasn't been updated since the CD was printed, the page is accessed from the CD instead, using a mechanism called Client-Pull. If the user has an Internet connection, selecting a link will cause the browser to request the page from the web server. However, if the page hasn't been changed since the pages on the HD were updated, a Redirection is issued by the server, reducing the problem to the non-Internet connected case.
This design relies on two forwarding mechanisms to get the correct document to the browser. Redirection is used by the web server to inform the browser that a more recent copy can be found locally. Client-Pull is used by the HD to inform the browser it should look on the CD instead. These mechanisms operate using features of HTTP, a protocol for transferring data between web browsers and web servers, and HTML, the language used to write web pages.
HTTP, the Hyper Text Transfer Protocol, is used by web browsers to retrieve web pages (and other objects, such as graphics) across the Internet [2]. It is a simple text-based request-response protocol that runs over a reliable data stream. Responses from the server contain a status code and a number of field-value pairs.
One possible HTTP response that a web server can return is the Redirection
response, which instructs the web browser that it must retrieve another
URL to fulfill the request. Different types of Redirections are possible;
the Moved Temporarily Redirection is useful in this design, since
it indicates the web browser should continue to check back with the web
site on future requests. Figure 1 shows an example of this response and
how it compares to a normal response in which a web page is returned. Redirections
are available in both HTTP 1.0 and 1.1, and are supported by all common
browsers.
|
Normal |
Redirected |
HTTP/1.1 200 OK Content-Type: text/html <html> HTML document continues... |
HTTP/1.1 302 Redirection Location: file://tmp/testfile Connection is closed. |
Figure 1. A normal HTTP response and a Moved Temporarily Redirection response. In the normal response, the HTTP code is 200, and the message is "OK." HTTP then indicates what the type of document it will send (in this case, HTML), and proceeds to send the document. In the Redirection response, the HTTP code is 302, which indicates a Redirection, and specifically a Moved Temporary one. The URL that the browser should redirect to is then given in the Location field. In both cases, other headers may be present.
Web pages are written in HTML, the Hypertext Markup Language, which is described in [3]. In a typical web browsing session, selecting a link results in an HTTP connection to a web server, over which a URL is requested and an HTML document is returned.
Client-Pull is a mechanism by which web pages can instruct web browsers to retrieve another document. This mechanism was designed unilaterally by Netscape and is described in [4]. While it is not part of any standard, it has been implemented in other web browsers such as Microsoft Internet Explorer and Lynx; it is likely to be available on most browsers used by the maintainer's colleagues. Those users for whom it is not available will only have to suffer the inconvenience of an extra mouse click to access a page on CD.
HTML 2.0 provides a META tag, which allows meta-information to be included in the document. One use of the META tag is the HTTP-EQUIV attribute, which allows the document to supply additional HTTP header information. Even if the document is retrieved from local disk rather than via HTTP, the browser should still act as if it contained the mentioned HTTP header.
The Client-Pull feature operates by using the HTTP Refresh header.
This header instructs the web browser to refresh the page, by reading a
new URL at some specified time in the future. By setting the new URL to
be on CD, and the time to be zero seconds, it can be used as a forwarding
mechanism; this is shown in Figure 2. An alternative that was considered
was the use of soft or symbolic links. However, these are only available
under certain operating systems and have varying semantics or present other
compatibility issues.
<META HTTP-EQUIV="Refresh" CONTENT="0; URL=file://page.html">
Figure 2. Using Client-Pull in an HTML document. This line instructs the browser to retrieve the document at URL file://page.html after waiting zero seconds.
The web page formats are the key to the operation of this design. These
pages are accessed both by the maintainer and his or her colleagues. For
every page in the web site, six different types of web pages are created.
These fulfill different roles, depending on whether the user has Internet
access or not, and which device they reside on; the types are summarized
in Table 2. Note that the abbreviations are derived from the Net and Location
fields in most cases. These abbreviations will be used throughout this
paper both in the text and as file name extensions in the examples. Each
type has a different role in making sure that the user always views the
most up-to-date page. In this section the structure of the individual pages
are described while the following section gives an example of how the pages
work together.
Table 2. Summary of web page formats.
| Name |
Abbr. |
Location |
Net |
Contents |
| Server forwarding stub |
SHD |
HD |
Yes |
Client-Pull to Server |
| Internet CD stub or updated page |
IHD |
HD |
Yes |
Client-Pull to ICD or Updated page |
| Non-Internet CD stub or updated page |
NHD |
HD |
No |
Client-Pull to NCD or Updated page |
| Internet CD page |
ICD |
CD |
Yes |
Web page |
| Non-Internet CD page |
NCD |
CD |
No |
Web page |
| Server Web page |
HTML |
Server |
Yes |
Web page |
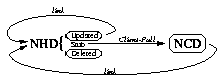
The NHD and IHD copies of a page are essentially the same, with the
only difference being where their links point to; the same goes for NCD
and ICD. IHD pages forward to ICD pages or link to SHD pages, while NHD
pages forward to NCD pages or link to other NHD pages. The purpose of having
an Internet and non-Internet version of the pages is to keep track of whether
the user has an Internet connection or not. There isn't a mechanism to
store arbitrary state information in web browsers, so typically the would
user have to select whether Internet access is available every time a link
was followed. By having two separate groups of pages, we store the state
in the pages themselves. Figure 3 shows the sequence of pages a browser
will traverse if the user does not have Internet access, while Figure 4
shows the equivalent for users without Internet access.
Figure 3. Paths a browser will take through the
web pages in a non-Internet environment. Rounded-rectangles indicate actual
HTML pages where the user can select a link.
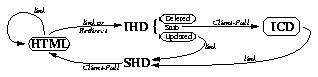
Figure 4. Paths a browser will take through the web pages in an Internet environment. The HTML pages on the left reside on the web server, the IHD and SHD pages in the middle reside on the hard drive, and the ICD pages on the right are on the CD.
As was mentioned, the Internet and non-Internet CD stub or updated pages (IHD and NHD) copies of a page are very similar. Both types reside on a user's hard drive, and take on one of a few forms:
By default the IHD and NHD pages are stub pages. When a web browser
attempts to read a stub, it will be forwarded to the corresponding page
on the CD by a Client-Pull. Figure 5 shows what an IHD stub page would
contain.
<META HTTP-EQUIV="Refresh" CONTENT="0; URL=file://cdrom/EGYPT/page.icd">
Figure 5. The contents of an IHD stub page. An NHD stub page would be identical, except the ".icd" in the destination URL would be a ".ncd" instead.
When the maintainer gives a copy of the CD to a colleague, there may be updated pages on the laptop's hard drive that he or she would like the colleague to have as well. If this is the case, the stubs are replaced by actual updated pages. This way, rather than being forwarded to the old copy of the page on the CD, the web browser will display the updated page from the HD. Links on an updated page point to other IHD/NHD pages to allow the browser to look for updated copies of these pages, or be forwarded to a version on CD.
Besides updating a page, the maintainer may also delete or move a page. The IHD/NHD of deleted pages will be a short HTML document that displays an error message. This prevents the browser from being forwarded to the now obsolete copy on the CD. While the stub could have just been deleted, replacing it with an error page allows the maintainer to provide user's with additional information. For example, a user may have a bookmark (a link from one of his or her own pages) that points to the deleted page; the error page could tell users to remove their bookmark, or where the new page is located. To move a page, the deletion procedure is performed on the page, and a new stub page which points to the old location on the CD is added.
Like Internet and non-Internet CD stub or updated pages (IHD and NHD),
Internet and non-Internet CD pages are also very similar. These pages,
which reside on the CD, contain the actual HTML data that was in the web
pages when the CD was created. ICD and NCD pages are identical in every
way but the destinations of their links. In fact, even the links are mostly
the same: the only difference is that ICD pages link to SHD pages, while
NCD pages link to the corresponding NHD page. Figure 6 shows the differences
in the URLs of ICD and NCD pages. Like IHD and NHD, these two classes of
pages exist only to preserve information about whether the browser has
an Internet connection or not.
|
NCD |
ICD |
file://EGYPT/page.nhd |
file://EGYPT/page.shd |
Figure 6. Sample URLs from links on NCD and ICD
pages. Note that the URLs differ only in file name extension.
NCD pages link to NHD pages, so clicking on a link will either result in an updated page being loaded from the hard drive, or the browser being forwarded to another NCD page on the CD. However, clicking on a link of an ICD page takes the browser to an SHD page, not an IHD page.
Since CDs have a fixed capacity of 650 Mb, and the primary web site under consideration contains 400 Mb of data, it is possible that duplicating every page is not possible. However, only HTML pages with links on them need to be duplicated, not graphics. Most of the space on the CD is likely devoted to storing graphics, even if there are more HTML pages [5].
If space is short, one page rather than two could be used. The only problem this creates is that the state information we are keeping (whether the user has an Internet connection or not) would be lost. Users would have to select a different link from the page depending on whether they had Internet connectivity or not, resulting in an extra decision each time a page is loaded from CD. Though this is not a large hassle, it could be minimized by eliminating duplicates of infrequently used pages, or pages with few links first.
When a user has Internet connectivity, the remote server needs to be
checked for more up-to-date versions of the page. Therefore, all ICD pages
(and any updated IHD pages) point to a server forwarding stub page on the
hard drive. If the user selects these links, the browser will first read
the SHD off of the hard drive, and then be immediately forwarded to the
web site. Figure 7 illustrates the contents of an SHD page.
<META HTTP-EQUIV="Refresh" CONTENT="0; URL=http://server/path/EGYPT/page.html?date=09181996">
Figure 7. The contents of an SHD page. This line
instructs the browser to retrieve the page from the remote web server after
zero seconds. The date that the pages on the HD were up-to-date as of is
provided to the web server to allow it to make a forwarding decision.
The reason that links point to the SHD pages rather than directly to the web server is as follows. The web server needs to be able to make a determination of whether its version of a page is newer than the one contained on the user's system. However, it only has the revision date of the page stored on the web server. To solve this, the date which the user's system was up-to-date as of (called the local revision date) is included as supplementary information in the URL that is sent to the web server. For updated pages on the hard drive, the date sent would indeed be the correct one: the date on which the colleague received the CD and updated pages from the maintainer. However, links originating on the CD would only be able to pass along the date at which the CD was created. By taking an indirect path via an SHD page on the hard drive, the web server is always provided with the correct local revision date.
The server web pages contain actual HTML data, much like the ICD/NCD pages on the CD. However, server pages may have been updated at any time relative to a particular web browser. Thus the particular appearance of a server web page depends on local revision date that the SHD passes to the web server.
First, the server web page may in fact be an HTTP Redirection rather than a web page at all. This case occurs if the web server determines that the user has a current version of the page on his or her machine; the procedure for this is explained in detail in the subsequent sections. If the web server does in fact send back an actual HTML page, it may also need to perform some translation on the URLs in links on the page, based on the local revision date that the browser provided. The reason and procedure for this translation is explained in Section 5.5, Server Modifications.
In order to make the operation of the system clearer, an example of
browser operation is presented in this section. In this example, the user
has Internet connectivity, and starts off on a page located on the CD.
The user clicks on a link to a page which hasn't been updated since the
CD was created, so the page ends up being loaded from the CD, after the
browser checks with the web server and HD. A timing diagram for network
and file system requests is shown in Figure 8.
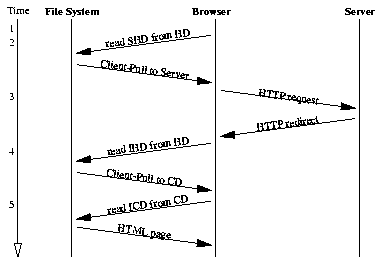
Figure 8. Timing diagram of browser/file system/server
interactions in the example.
In order to support this design, a few modifications need to be made to the web server where the pages are located. The changes are fairly simple, and can be implemented easily by modifying the source code (since most web servers are distributed freely with source) or using external program interfaces such as CGI [6].
When the server receives a query for a page, it looks to see if a date has been included with the URL. The format used is the same as the one for HTTP GET method form submissions: a question mark, the variable name, an equals sign, and the variable value are appended to the URL. The server then looks up the date that the version of the page on the server was modified at (the server page date). This is stored as a comment in the HTML file, but could also be placed in a separate table for performance reasons, or recorded by the file system if support for this is available. If the local revision date received with the URL is later than the server page date, the user has a copy that is as up-to-date (or perhaps even more recent) than the one on the server; the server responds with an HTTP Redirection to the IHD copy of the page. If the server doesn't have a copy of the requested page, and the local revision date is newer than that of any page the server has, the user's machine may have a copy of the file, so it sends a Redirection in this case as well.
Since the pages may be installed in different places on the hard drive, depending on the operating system and configuration of the user's computer, the server needs to have a way to find out the exact URL to forward the browser to. Fortunately, all HTTP connections that require Redirects will have just been forwarded to the server from an SHD page on the user's hard drive. All popular browsers send an HTTP Referrer header field, which indicates the previously accessed page. So, if the referring page is file://path/page1.shd, the browser copies the path and substitutes in the new page to get file://path/page2.ihd.
If the local revision date is earlier than the server page date, the user's copy is older than the one on the server. In this case, the server will return a copy of the new page. A problem can arise here: since the page has been updated more recently than any of the pages on the user's hard drive, it may have links to pages created after the local revision date. If the URL in a one of these links pointed back an IHD page, the browser wouldn't find a Internet CD stub or updated page on the HD, and the user would receive an error. However, it is fairly easy to fix this problem: the web server knows the local revision date of the user's machine, and can look up the server page dates of all the pages that the current page links to. If the server page date of a linked to page is earlier than the local revision date, it provides a link to the IHD page on the users hard drive. Otherwise, if the copy of the page on the web server is newer, it provides a link to the web server page. This substitution is made dynamically when a browser requests a page. Not only does this eliminate the problem of the user not having new pages, it also skips the IHD-ICD-SHD-HTML loop by going straight back to HTML (see Figure 4).
For each web page that is written, many pages need to be generated: IHD, NHD, ICD, NCD, SHD, and HTML versions must all be produced from time to time. While the maintainer could create each one by hand from a list of instructions, providing a set of tools makes this task much easier. In this section procedures are outlined for using and implementing tools for updating, adding, deleting, and moving pages. In the following sections we extend these tools to permit updating the web server, creating a CD, and giving copies of the CD and any updated pages to colleagues.
Updating a page can be assisted by a simple program which could be written in a simple, interpreted language; it would work as follows. If the page has already been updated since the CD was created, the existing copy on the laptop is used. Otherwise the program makes a copy of one of the CD versions (ICD or NCD), replacing links to specific URLs, which contain text before the page name and an extension after the page name (e.g. file://path/EGYPT/pageX.shd) with generic URLs, which consist of only the name (e.g. pageX). The maintainer is then free to edit the file using a text or HTML editor. Any new links he or she adds should also be to generic URLs. Adding a page works the same as updating a page, except that the maintainer starts off with a blank file, rather than an existing page.
When the maintainer is done, the program generates IHD and NHD versions by replacing the generic URLs with specific URLs. Links on IHD pages will point to SHD pages while links to NHD pages point to other NHD pages. An SHD page is also generated by converting the generic URL of the page being edited to a specific URL on the web server, and appending the current date. In fact, all the SHD pages that the maintainer has need to have their copy of the local revision date updated, since the date is used not just for that specific page, but as an indication of how up-to-date the hard drive is in general.
To delete a page, the maintainer invokes a delete program. This program will remove the NHD and IHD pages on the hard drive (which are either CD stubs or updated pages), and prompt the user for an error message. This message can be used to alert users as to why the page was deleted, and where a new version might be found. The program then updates all SHDs with the current date; this may seem unnecessary but is required to propagate deletions. If the local revision date in the SHDs was not updated, the web server would be given the wrong date, and might return a server web page that it believes is up-to-date, when in fact the most recent version is the deleted page on the user's hard drive.
The tool that moves pages takes the current and new locations of the page as arguments. It copies the NHD and IHD to their new locations, and replaces them with an error message selected by the maintainer. If the page had been updated on the hard drive, the new location contains a copy of the page. Otherwise, only a stub pointing to the old NCD or ICD is copied. This is preferable to copying the page from CD to the new location, since that would unnecessarily use extra hard drive space. Under the general web model, moving pages breaks relative URLs used on the page and links to the page. The same happens under this design: relative URLs and links on other pages must be updated. However, the tool that moves pages could provide added functionality by updating the maintainer's pages automatically. The program then replaces the local revision date in all SHDs with the current date.
To create a CD, the CD creation program first copies the contents of the previous CD (NCD and ICD pages) to a writable directory on a hard drive. If this is the first CD being made, this area will be empty. The program then goes through the NHD/IHDs on the hard drive, and updates this directory. If an NHD/IHD contains a CD stub, the page is left alone. If it contains an updated page, the program replaces the old NCD/ICD page with it, modifying the link URLs (to be suitable for placement on a CD) as it does so. If it contains a deleted page, the program deletes the old NCD/ICD page. If it contains a moved page, a copy of the old page to a new location needs to be made; this could either be done in a pass before deletions, or by recopying these pages from the CD. Moved pages can be recognized by inconsistent generic URLs: the stub would be in the location for pageX while the URL it forwards to is pageY. A new CD can now be made with the contents of this directory area.
When the maintainer begins using this new CD, the old NHD, IHD, and SHD pages on the laptop's hard drive will need to be deleted, and stubs regenerated from the new CD. Deletion is simple: all of the NHD, IHD, and SHD files can be purged. Regenerating the stubs is also fairly easy. A tool goes through the NCD/ICD files on the CD, and generates NHD, IHD, and SHD stubs from the information in them: NHD files contain a Client-Pull to the NCD files; IHD files contain a Client-Pull to the ICD files; and SHD files contain a Client-Pull to a server web page. Of course, these files may not be on the web server yet, but since the server has been programmed to respond to a request for a missing file by returning a Redirection (if the browser indicates it has newer data the server), a browser accessing the SHD file will end up displaying the ICD file.
Giving colleagues a copy of the web pages is quite easy, since the maintainer has been browsing the web pages in the same manner colleagues will. First the maintainer gives a colleague the current CD. Then the maintainer copies over all the NHD, IHD, and SHD files from the laptop to the colleague's computer. These files contain stubs and also updated pages. Since the files are all ordinary (either text or binary), they can be copied in a number of ways: by floppy disk, across a local area network by FTP, through a local file server, via a serial interface, etc. Most of these methods could be automated and integrated into a tool for automatic installation.
A possible extension of this scheme is to make a provision only giving a CD to a colleague. This may be useful to the maintainer if he or she cannot spend the time to provide the updated pages, or has no way of getting them to the colleague. To do this, a copy of the default stub pages would just be included on the CD; this would require very little storage compared to the actual pages. The maintainer's colleagues could then copy the stubs from the CD on to the local disk themselves.
Updating the web server is similar to creating a CD: in both cases a program checks for differences between what the data is like now and what it should be like, and then makes the necessary adjustments. However the procedure is a little easier for creating a CD, since any updated pages on the hard drive have been changed since the last time a CD was created; there may be updated pages on the hard drive which have already been updated on the web server, if updating the web server occurs more frequently than creating CDs. It is assumed that the web server will be updated before creating a CD, otherwise date stamp information is lost. This should not be a problem, since creating a CD can only be done in "carefully controlled environment," which is likely to have Internet access [7]. Even if this update is not done, the server can still be updated by deleting all pages before starting; all pages will be updated.
The modification to the CD creation procedure is that as it examines each NHD/IHD page, it also requests the corresponding page from the web server and checks the server page date. If the web server has the same version as the NHD/IHD page, that page doesn't need to be updated. This modification works for both updated or deleted NHD/IHD pages; we can ignore stub pages because the server was updated when the CD was created, so the web server already has a copy of any page that is on the CD.
The proposed design satisfies all critical requirements as well as the features necessary for the system to be deployed and maintained successfully. While the design sacrifices internal simplicity, it does so in order to make operation as easy and transparent as possible; it is better to place the complexity where a professional programmer can handle it, rather than force an Egyptologist and his or her colleagues to deal with it. In fact, the design is based on a simple idea: have the web browser find and display the most up-to-date information; it is the lack of flexibility in the Web model from which difficulties arise.
My thanks go to Susan Dey and Joe Foley, with whom I discussed alternate approaches to solving this problem. Christopher Bachmann and Joung-Mo Kang permitted me to use their computers for testing. Special thanks to Craig Barrack, my Algorithms instructor, who provided me with a problem set extension that allowed me to complete this paper.