Conversion for data manipulation R-Python conversion guide
Main concepts
File management The table below summarizes useful commands to make sure the working directory is correctly set:
| Category | R command | Python command |
| Paths | setwd(path) | os.chdir(path) |
getwd() | os.getcwd() | |
file.path(path_1, ..., path_n) | os.path.join(path_1, ..., path_n) | |
| Files | list.files(path, include.dirs = TRUE) | os.listdir(path) |
file_test('-f', path) | os.path.isfile(path) | |
file_test('-d', path) | os.path.isdir(path) | |
read.csv(path_to_csv_file) | pd.read_csv(path_to_csv_file) | |
write.csv(df, path_to_csv_file) | df.to_csv(path_to_csv_file) |
Chaining Successive operations can be chained in R using the %>% symbol in order to provide better legibility. It is done as follows:
# df gets some_operation_1, then some_operation_2, ..., then some_operation_n
df %>%
some_operation_1(params_1) %>%
some_operation_2(params_1) %>%
... %>%
some_operation_n(params_1)
The corresponding Python command is as follows:
# df gets some_operation_1, then some_operation_2, ..., then some_operation_n
(df
.some_operation_1(params_1)
.some_operation_2(params_2)
. ...
.some_operation_n(params_n))
Exploring the data The table below summarizes the main functions used to get a complete overview of the data:
| Category | R command | Python command |
| Look at data | df %>% select(col_list) | df[col_list] |
df %>% select(-col_list) | df.drop(col_list, axis=1) | |
df %>% head(n) / df %>% tail(n) | df.head(n) / df.tail(n) | |
df %>% summary() | df.describe() | |
| Data types | df %>% str() | df.dtypes / df.info() |
df %>% NROW() / df %>% NCOL() | df.shape |
Data types The table below sums up the main data types that can be contained in columns:
| R Data type | Python Data type | Description |
character | object | String-related data |
factor | String-related data that can be put in bucket, or ordered | |
numeric | float64 | Numerical data |
int | int64 | Numeric data that are integer |
POSIXct | datetime64 | Timestamps |
Data preprocessing
Filtering We can filter rows according to some conditions as follows:
| Category | R command | Python command |
| Overview | df %>% filter(col operation val_or_col) | df[df['col'] operation val_or_col] |
| Operation | == / != | == / != |
<, <=, >=, > | <, <=, >=, > | |
& / | | & / | | |
is.na() | pd.isnull() | |
%in% (val_1, ..., val_n) | .isin([val_1, ..., val_n]) | |
%like% 'val' | .str.contains('val') |
Changing columns The table below summarizes the main column operations:
| Action | R command | Python command |
| Add new columns on top of old ones | df %>% mutate(new_col = operation(other_cols)) | df.assign( new_col=lambda x: some_operation(x) ) |
| Unite columns | df %>% unite(new_merged_col, old_cols_list) | df['new_merged_col'] = ( df[old_cols_list].agg('-'.join, axis=1) ) |
Conditional column A column can take different values with respect to a particular set of conditions with the following R command:
case_when(condition_1 ~ value_1, # If condition_1 then value_1
condition_2 ~ value_2, # If condition_2 then value_2
...
TRUE ~ value_n) # Otherwise, value_n
The corresponding Python command is as follows:
np.select(
[condition_1, ..., condition_n], # If condition_1, ..., condition_n
[value_1, ..., value_n], # Then value_1, ..., value_n respectively
default=default_value # Otherwise, default_value
)
Mathematical operations The table below sums up the main mathematical operations that can be performed on columns:
| Operation | R command | Python command |
| $\sqrt{x}$ | sqrt(x) | np.sqrt(x) |
| $\lfloor x\rfloor$ | floor(x) | np.floor(x) |
| $\lceil x\rceil$ | ceiling(x) | np.ceil(x) |
Datetime conversion Fields containing datetime values are converted from string to datetime as follows:
| Action | R Command | Python Command |
| Converts string to datetime | as.POSIXct(col, format) | pd.to_datetime(col, format) |
where format is a string describing the structure of the field and using the commands summarized in the table below:
| Category | Command | Description | Example |
| Year | '%Y' / '%y' | With / without century | 2020 / 20 |
| Month | '%B' / '%b' / '%m' | Full / abbreviated / numerical | August / Aug / 8 |
| Weekday | '%A' / '%a' | Full / abbreviated | Sunday / Sun |
'%u' / '%w' | Number (1-7) / Number (0-6) | 7 / 0 | |
| Day | '%d' / '%j' | Of the month / of the year | 09 / 222 |
| Time | '%H' / '%M' | Hour / minute | 09 / 40 |
| Timezone | '%Z' / '%z' | String / Number of hours from UTC | EST / -0400 |
Data frame transformation
Merging data frames We can merge two data frames by a given field as follows:
| Category | R command | Python command |
| Overview | merge(df_1, df_2, join_field, join_type) | df_1.merge(df_2, join_field, join_type) |
| Join field | by = 'field' | on='field' |
by.x = 'field_1', by.y = 'field_2' | left_on='field_1', right_on='field_2' | |
| Join type | all.x = TRUE | how='left' |
all.y = TRUE | how='right' | |
default | how='inner' | |
all = TRUE | how='outer' |
Concatenation The table below summarizes the different ways data frames can be concatenated:
| Type | R command | Python command |
| Rows | rbind(df_1, ..., df_n) | pd.concat([df_1, ..., df_n], axis=0) |
| Columns | cbind(df_1, ..., df_n) | pd.concat([df_1, ..., df_n], axis=1) |
Common transformations The common data frame transformations are summarized in the table below:
| Type | R command | Python command |
| Long to wide | spread( df, key = 'key_name' value = 'value_name' ) | pd.pivot_table( df, columns='key_name', values='value_name', index=other_cols, aggfunc=np.sum ) |
| Wide to long | gather( df, key = 'key_name', value = 'value_name', c(key_1, ..., key_n) ) | pd.melt( df, var_name='key', value_name='value', value_vars=[ 'key_1', ..., 'key_n' ], id_vars=some_cols ) |
Row operations The following actions are used to make operations on rows of the data frame:
| Action | R command | Python command |
| Sort data frame | df %>% arrange(col_list) | df.sort_values(by=col_list, ascending=True) |
| Drop duplicates | df %>% unique() | df.drop_duplicates() |
| Drop rows with null values | df %>% na.omit() | df.dropna() |
Aggregations
Grouping data A data frame can be aggregated with respect to given columns as follows:
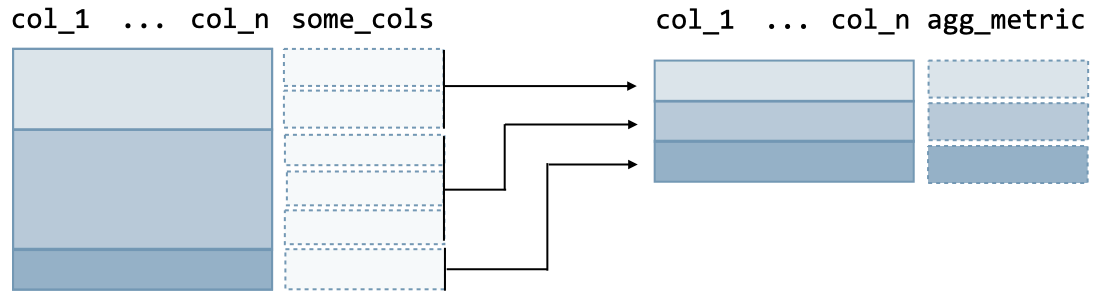
The R command is as follows:
df %>% # Original ungrouped data frame
group_by(col_1, ..., col_n) %>% # Group by some columns
summarize(agg_metric = some_aggregation(some_cols)) # Aggregation step
and the Python command is as follows:
(df # Original ungrouped data frame
.groupby(['col_1', ..., 'col_n']) # Group by some columns
.agg({'col': builtin_agg})) # Aggregation step
where builtin_agg is among the following:
| Action | R Command | Python Command |
| Count across observations | n() | 'count' |
| Sum across observations | sum() | 'sum' |
| Max / min of values of observations | max() / min() | 'max' / 'min' |
| Mean / median of values of observations | mean() / median() | 'mean' / 'median' |
| Standard deviation / variance across observations | sd() / var() | 'std' / 'var' |
Window functions
Definition A window function computes a metric over groups and has the following structure:
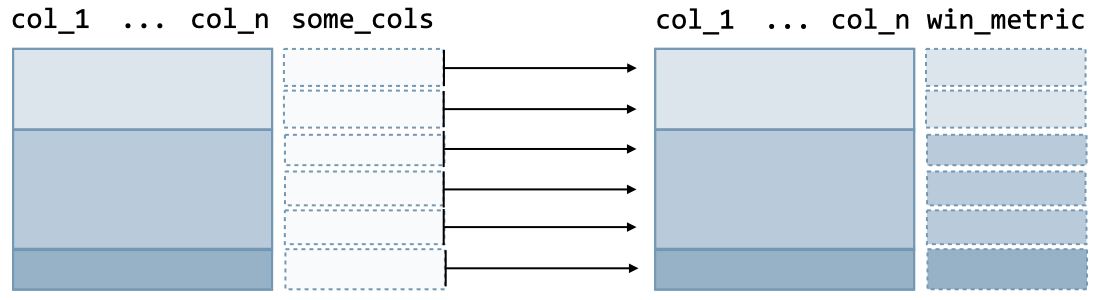
The R command is as follows:
df %>% # Original ungrouped data frame
group_by(col_1, ..., col_n) %>% # Group by some columns
mutate(win_metric = window_function(col)) # Window function
and the Python command is as follows:
(df
.assign(win_metric = lambda x:
x.groupby(['col_1', ..., 'col_n'])['col'].window_function(params)))
Remark: applying a window function will not change the initial number of rows of the data frame.
Row numbering The table below summarizes the main commands that rank each row across specified groups, ordered by a specific field:
| R Command | Python Command | Description |
row_number(x) | x.rank(method='first') | Ties are given different ranks |
rank(x) | x.rank(method='min') | Ties are given same rank and skip numbers |
dense_rank(x) | x.rank(method='dense') | Ties are given same rank and do not skip numbers |
Values The following window functions allow to keep track of specific types of values with respect to the group:
| R Command | Python Command | Description |
lag(x, n) | x.shift(n) | Takes the $n^{\textrm{th}}$ previous value of the column |
lead(x, n) | x.shift(-n) | Takes the $n^{\textrm{th}}$ following value of the column |