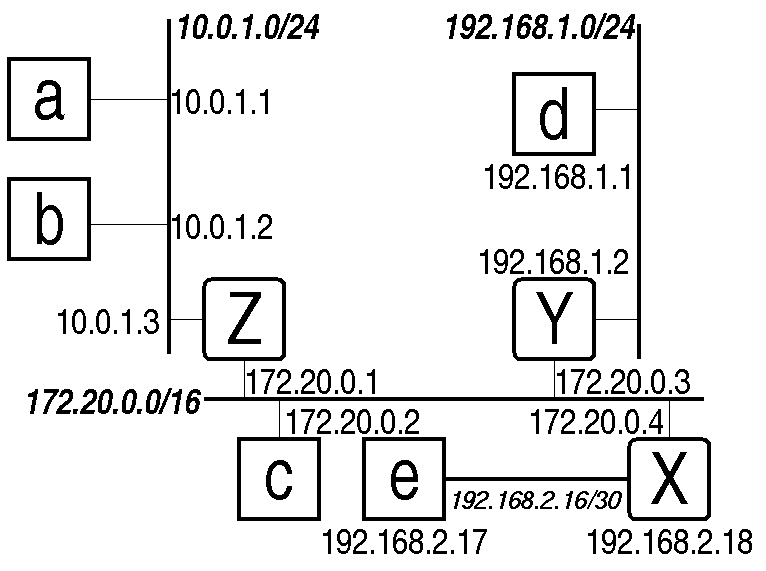
Each destination on the Internet gets an address. Most people think of destinations as hosts, but in fact hosts can be attached to the network in multiple places, and each interface of a host is a destination. So, we assign an address to every interface on the Internet.
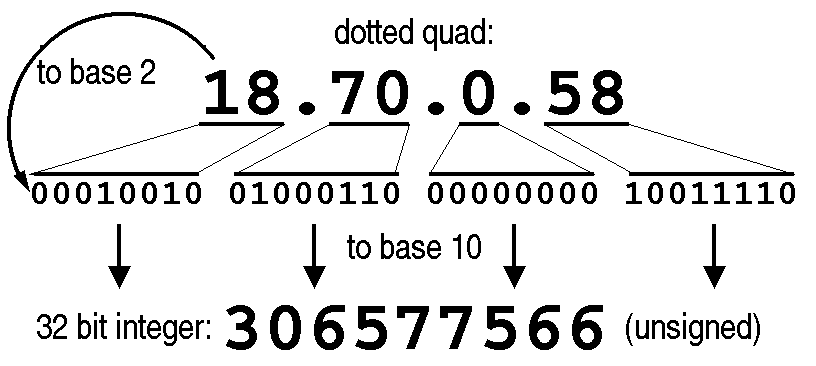
IP addresses are 32 bits (4 bytes) long. This allows for 2^32 or 4294967296 (4.3 billion) different combinations. Internet addresses are most commonly seen in something referred to as "dotted quad notation". In this format, the 32-bit number is written as 4 8-bit decimal numbers, separated by periods. An example of this is "18.70.0.58". Internally, most computers will represent it as a 32-bit binary number - this is accomplished by converting each of the parts of the quad to binary and concatenating them. Very rarely one will also see the entire address written out as one decimal number, perhaps has part of a debugging print out.
Prefixes (sections of the network that are topologically close) are expressed by giving an address, and the number of bits of the address that all hosts in the section have in common. For example, all hosts on MITnet have addresses starting with 18 (the addresses are of the form 18.*.*.*.), so a prefix expressing this would be 18.0.0.0/8 (to imply the 8 left bits are in common), or 18.0.0.0 255.0.0.0 (where the length is expressed as a left-aligned bit-mask), or simply 18/8. All the hosts in Building E52 have addresses starting with 18.42., so 18.42/16 or 18.42.0.0 255.255.0.0 are ways the prefix might be described.