6.005 Elements of Software Construction | Spring 2011
|
The purpose of this problem set is to give you practice in writing representation invariants.
Binary Search Trees are fundamental data structures in Computer Science, and are frequently used to store a sequence of some numbers (or more generally, some “keys”) in sorted order.
You can read more about Binary Search Trees on Wikipedia: http://en.wikipedia.org/wiki/Binary_Search_Tree
The 6.006 website also has notes on Binary Search Trees: http://courses.csail.mit.edu/6.006/spring11/notes.shtml
Here are a few essential things you need to know about Binary Search Trees for this problem set:
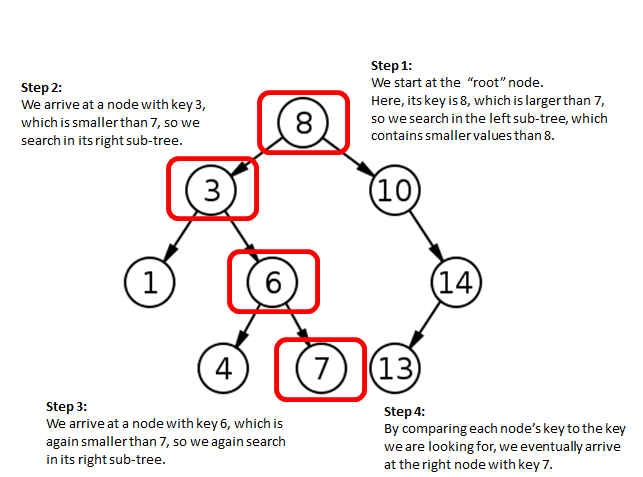
Binary Search Trees are useful because they speed up lookup of data. For example, if we want to find out whether a particular number is in a Binary Search Tree, we do not need to look through all the elements in the tree. In fact, we can get away with only looking through elements on a single path from the “root” node to a “leaf”. The number of elements on a single path from the root to a leaf is usually much less than the total number of elements in the entire Binary Search Tree.
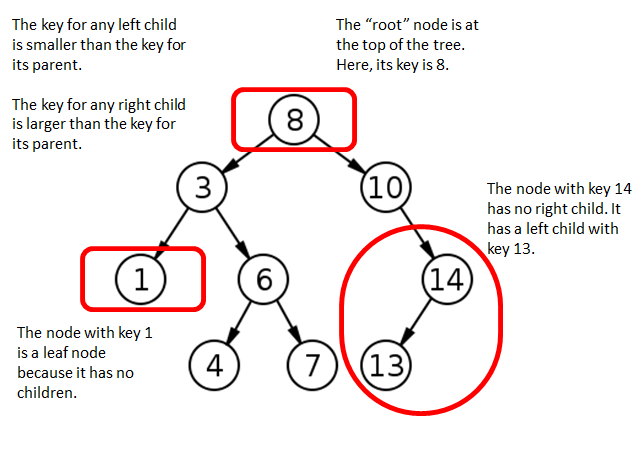
The minimum key in a Binary Search Tree is that of the left-most node (which we can reach if we keep following “Left Child” arrows). For instance, the minimum key in the example Binary Search Tree in Figure 2 is 1. Similarly, the largest key in a Binary Search Tree is that of the right-most child (which we can reach if we keep following “Right Child” arrows). In Figure 2, the maximum key is 14.
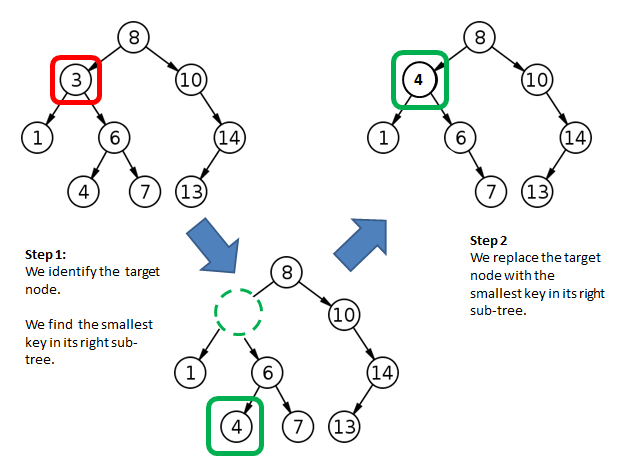
There are three cases to consider while removing node from a Binary Search Tree:
These cases are illustrated in the figures below, respectively.
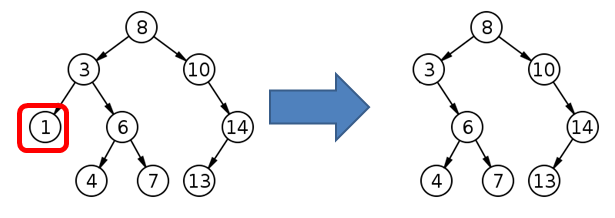
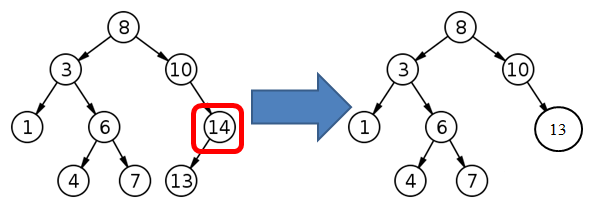
Read the source code provided in the ps2.bst_simple and ps2.bst_exception packages. Specifically, read and understand BinarySearchTree.java, BinaryNode.java, BinarySearchTreeTester.java, DuplicateItemException.java and ItemNotFoundException.java.
Tasks:
Once you’re done, make sure your code passes all the test cases in BinarySearchTreeTester.java.
For this problem, only read and modify the source code provided in the ps2.bst_arbitrary_keys package.
Our current Binary Search Tree implementation is only capable of storing integers. Naturally, we would like to extend our implementation so that we can store arbitrary objects in our Binary Search Trees (such as Strings and instances of user-defined classes). In other words, we would like to decouple our code for Binary Search Trees from the specific types of objects we store in our trees as keys.
Think about how you would achieve this decoupling, before you go ahead with this problem.
A complete solution that achieves decoupling would use Generics and Java’s inbuilt Comparable<T> interface. However, considering what we have covered in the class so far, we will ignore these options and use our own interface for this purpose. This interface is defined in BinaryTreeItem.java; read and understand it.
Tasks:
Hint: Consider what should happen in compareTo(...) if the supplied argument is an instance of a different subclass of BinaryTreeItem? This case can be effectively specified using a combination of @requires and @throws. Reading up on Java’s ClassCastException may help.
As before, implement a checkRep() method for the modified BinarySearchTree class, and make sure to add calls to checkRep() in the right places. Also copy over the specs from part A, and modify them wherever necessary.
Complete the implementation of the following classes, in order:
Hint: Read the methods in the test suite carefully. We provide methods that you can use to generate random Strings or Students, and utility functions to find the minimum or maximum of elements in a List of any type.
For this problem, only modify the source code provided in the ps2.bst_augmented_abstract package.
So far, we have described and implemented Binary Search Trees with no special properties: nodes were simply sorted and arranged by key values.
Now, we will extend the functionality of our Binary Search Trees to create Augmented Search Trees. Augmented Search Trees are special types of Binary Search Trees that, apart from maintaining a sorted order of elements (based on their keys), also track some information about elements based on where these elements are stored in Binary Search Trees. We provide an abstract class for augmented search trees in AugmentedBinarySearchTree.java.
Augmented Binary Search trees have numerous applications, but we will focus on a few simple examples. For this part, you will encounter three different Augmented Binary Search trees:
The first augmented search tree simply stores, at each node, the number of descendant nodes below it (excluding the node itself). This information must be dynamically updated during insertion and deletion of elements from the Binary Search Tree, without needing to visit all of the elements in the tree. A working implementation of this augmented tree is provided to you in NumberDescendantsBinarySearchTree.java. This implementation uses code from the AugmentedBinarySearchTree class, and is thus surprisingly simple.
The second augmented tree stores, at each node, the sum of the keys of all descendant leaves below it (excluding the node itself). A leaf node is defined as a node that has no descendant nodes. Note that a tree with a single node should have an augmented value of 0, since the node has no descendant leaves. This information must again be dynamically updated during insertion and deletion of elements as before, without having to visit all the elements in the tree. It will be your job to fill in code for this augmentation in LeafSumBinarySearchTree.java.
The third and final augmented tree stores, at each node, the range of values stored in the subtree containing the node (that is the difference between the max and min values). Again, this information must be dynamically updated during insertion and deletion of elements, without having to visit all the elements in the tree. Note that in this case we have given you a new class to work with, RangeBinaryNode.java, which in addition to the augmented value (representing the range) stores the value of the minimum and maximum elements in the tree. It will be your job to fill in code for this augmentation in RangeBinarySearchTree.java to update the augmented value (range), along with the minimum and maximum.
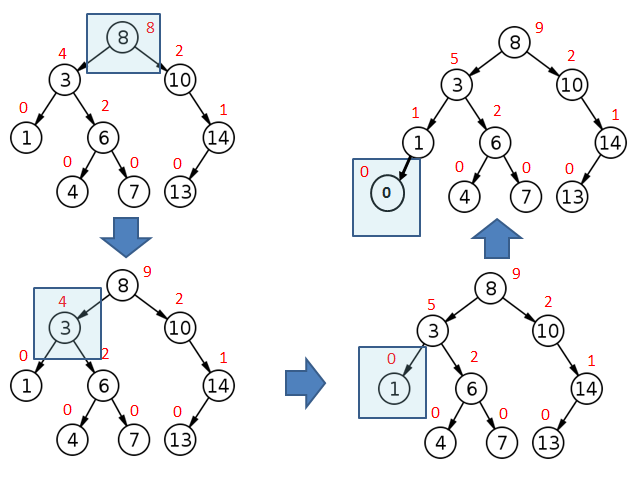
In general, there are two ways to handle augmentation. In some cases, it is possible to update information stored at each node as we walk down the pointers to a leaf or a node during insertion or deletion. Figure 4 illustrates how augmented data can be updated during an insertion.
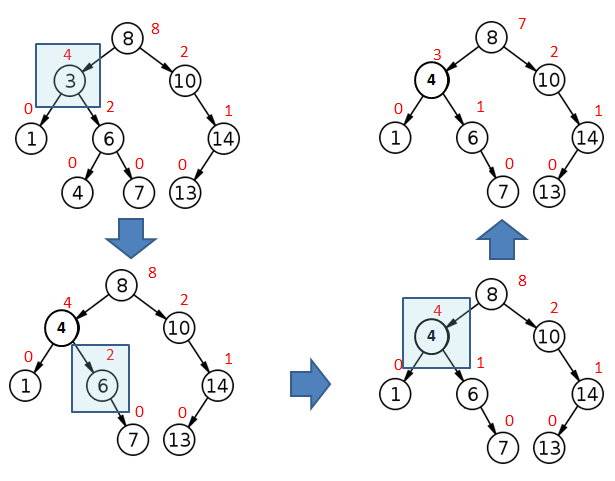
An alternative way to handle augmentation is to find the lowest element in the path along which an insertion or deletion occurred, and to propagate changes from that element upwards. This works because as long as we have accurate augmented values for a Node’s children, its own value can be easily computed, and any changes can be propagated upwards. Figure 5 illustrates an example of this for the deletion case which we saw in Figure 3c.
For this part, we provide an abstract class that handles all the described complexity associated with implementing Augmented Search trees and dynamically updating augmentation.
Read the code provided and make sure it makes sense to you, because it’s a good example of how an abstract class can provide code that handles complicated corner cases, so that a subclass only has to provide code for one/two simpler methods.
Tasks: