






Section 2.4.4
Design and Feasibility Reports
Design and feasibility reports describe one or more design solutions to a specific problem and determine if the proposed solution is practical and
feasible. Preferably, more than one solution is offered, in which case the report compares the
various designs and determines which option is best.
Design and feasibility reports are essentially the same type of document, differing only in the
amount of emphasis placed on practical and economic viability of the design in comparison with
other possible solutions. A design report, often very similar to an internal proposal, focuses on describing one specific implementation. A
feasibility study, on the other hand, also emphasizes the investigation and comparison of
alternative solutions.
Design reports and feasibility reports are crucial for decision making and product development in
almost any technical organization. They document an engineer's thinking through a solution to a
problem, a description of the solution, and the reasons why that solution should be implemented.
Managers need accurate and comprehensive feasibility and
design reports to decide where to commit scarce resources. In addition, an accurate and comprehensive design report helps in developing
other documents, such as formal proposals, specifications, and work plans.
Format of Design and Feasibility Reports
Most design and feasibility reports contain the following elements:
- An abstract that concludes with a short summary
of the recommended design.
- An introduction that presents the context of the
situation and then gives a clear and concise statement of the problem to solved.
- A list of design criteria, in order of importance
with the most important first. Clear and concise design criteria are crucial to any
design process. They establish the standards by which it possible to determine
whether a specific design is successful and to decide intelligently among competing
designs.
- Descriptions of possible implementations. A design report will often describe only
one possible implementation. A feasibility report will often present several
possible designs.
- A recommendation with a comparison of
alternatives. If a design report does not present any alternative designs, it should
still explain the reasons for specific design choices with respect to the design
criteria. Feasibility reports usually present one (or sometimes two)
recommendations and argue for the recommended solution by showing how it best
meets the stated criteria. Graphic devices, such as
a table listing how each implementation meets
each design criterion, are very effective in summarizing the reasons for the specific
design recommendation.
- Elaboration of design. Design reports and feasibility reports often then give a
more detailed description of the recommended design.
- Conclusion with recommendations for further
actions and a listing of issues that must be resolved before the design can be
implemented.
An example of a design and feasibility report follows.
A HyperText Filing Proxy
| Debajit Ghosh |
| Professor Agarwal |
| REC TR 2pm |
| March 21, 1996 |
An Improved HyperText Filing Proxy
Abstract
This paper discusses a proposed design for a large-scale caching system for World Wide
Web (WWW) pages. After examining the criteria the caching system should achieve, this paper
reveals some of the issues and possibilities inherent in such a caching system. It then presents
the decisions made in the new improved HyperText Filing Proxy (HTFP) WWW caching system
and compares HTFP to other web caches used today.
1 Introduction
If the dramatic growth of the number of web sites in the world (from 130 to 90,000 sites between
June 1993 and January 1996 [1]) is any indication, web traffic clearly
accounts for more and more of the traffic on the Internet. Since much of that consists of
repeated requests for the same pages from different clients, a caching system could reduce the
amount of traffic on the net. This reduction not only helps to relieve load on network servers
but also becomes a necessity when traffic is costly.
At the time if this writing, NEARNET is considering charging the MIT community per byte
transmitted across the link to the Internet it provides to MIT. As one might imagine, this could
get very expensive for a community that transfers 40,895,505 kilobytes a day [2] from the Internet, so reducing the amount of this traffic becomes a key issue. As mentioned, caching web
pages can reduce the amount of traffic on the net; this can save the MIT community a
considerable amount of money. Obviously, relying on an individual browser's caching system for
a single user would not suffice; these caches are quite volatile and are typically much smaller
than necessary to make a significant reduction in the amount of web traffic across a network.
Thus, we developed an improved Hyper Text Filing Proxy (HTFP) to provide such a large-scale
caching system. Basically, HTFP is a proxy server; all web requests are sent to the specified
proxy server, which either returns a cached version of the requested page or retrieves a fresh one
from the source. This paper outlines many of the issues considered in the design process,
highlights and describes the features of HTFP, and compares HTFP to several other existing
WWW caching systems.
2 Background
Before describing how the HTFP system caches web pages, let me give you some background on
the workings of the World Wide Web. This section will explain how the web works and describe
an important part of many web servers known as a proxy server. I assume that the reader has at
least used a web browser and done a minimal amount of exploration on the World Wide Web.
When a user clicks on a URL (Uniform Resource Locator, an address of a page on the web) in
his or her browser, the browser opens a TCP connection to the URL's target web server and
sends a request for the page.
. . .
Many networks now exist behind "firewalls," security systems that block incoming and/or outgoing
traffic. For this reason, individual users' machines cannot send web packets to the rest of the
network and browse web pages on the WWW. These networks usually provide a machine known
as a proxy server that can transmit and receive information through the firewall. This server
accepts web requests from clients within the network, retrieves the requested web pages, and
returns them to the clients. Proxy servers can also be useful in environments not restricted by a
firewall, as this paper will explain.
3 Design Criteria
An ideal web caching system would retrieve a web page from an external server only once, place
it in a cache, serve the cached copy transparently to clients requesting that page, and
automatically update the cached copy whenever the original has been modified. Of course, no
web caching system can flawlessly realize all of these features. Accordingly, HTFP prioritizes the
features it wishes to achieve from among the ones mentioned above.
Specifically, the most important criterion is that HTFP reduce the amount of web traffic between
MIT and NEARNET. The next important criterion is that the system be user-transparent; users
should notice a difference between retrieving pages from their source or retrieving them from the
cache. In addition, users should not get stale (outdated) copies of web pages from the cache.
Finally, the caching system should be robust, efficient, and as simple as possible while still
meeting the other criteria.
4 Design Issues and Considerations
HTFP represents but one of many possible implementations of a caching system that attempts to
meet the above criteria. In fact, it represents a mixture of many ideas and possible
implementations of such a system. In order to understand the thought process behind the design
of HTFP, we must first review some of the other possibilities and compare them to the
mechanisms present and implemented in HTFP.
4.1 Proxy vs. Transparent
Most global web caching systems (as opposed to the personal cache that each browser maintains
for a specific user) implement the caching system system through a proxy server within the
client's network. Because of the popularity of firewalls in network, proxy servers are already
popular, and their very nature makes them an obvious place to implement a cache; the cache
system could simply intercept web requests and return cached results rather than actually
forwarding the request to the content provider. After much consideration we decided to
implement our web caching system on a proxy server as well. We did, however, consider the
alternatives and ramifications of our decision, as explained below.
. . .
5 Implementation details
This section will outline the exact process by which a web request is handled and discuss other
details and features of the HTFP system. First, the client, who is configured to use the master
proxy as the HTTP proxy server for web servers outside the mit.edu domain, sends a request to
the master proxy server. Based on whether the destination is a .com, a .edu, or another type of
site (including straight IP address, the master proxy server forwards requests to a sub-pool of
proxies (probably about three servers in each pool). One proxy server is chosen randomly from
this sub-pool and receives this request.
The chosen proxy then determines whether or not the request is cachable as described above. If
it is not, the proxy opens a connection to the external server, retrieves the data, and immediately
returns the response to the client. Otherwise, the proxy uses an arbitrary hashing function to
hash the URL and checks the top-level index of its cache for the page. This index contains the
URL, title (if the page is an HTML document), two-character hash code, and actual file on the
server for each page. The index is organized by hash code; the proxy can save time by initially
checking only the appropriate section based on the hash code of the requested URL. If this
fails, the proxy then hashes the referring URL. For component data, such as images, the referer
header [14], used by the dominant browsers such as Netscape, contains the URL of the
component's associated document which it checks against the corresponding section of the index.
If this check fails, the proxy then scans its top-level index; it also sends RPC messages to the
peer proxies in its subpools, asking each to check their own caches for the URL and return a
find. . . .
6 Comparison with other caching systems
HTFP borrows and shares many ideas and features with other web caching systems.
Implementing the cache in a proxy server is one of the easiest, most networkfriendly methods, in
terms of slowing down the network. Given the structure and information provided by the HTTP
protocol, there are a limited number of ways to address the concern about the expiration and
validity of cached data. . . .
Some of the other popular or well-designed web caching systems in use today include W3C httpd,
the Harvest cache, and DEC's web relay. Of these, the former two are the most popular and
widely used today, with the Harvest accelerator gaining more and more popularity daily.* W3C httpd and DEC's web relay are rather similar; the caching system is implemented in a single proxy server and distribution of the load complicates the system if maintaining a consistent cache among the servers is desired. Harvest explores and implements some of the
hierarchicalcaching system ideas considered and discussed in this paper, such as having
cache-misses on an individual proxy propagate to higher-level servers. HTFP probably most
closely resembles the Harvest cache; however, even these two systems contain significant
differences. Table 1 provides a comparison between the key distinguishing features of the above
proxy-based caching systems. Following the table is an explanation of the presented criteria.
Table 1: Comparison of HTFP with other popular web caching systems
|
Transparent |
reduce traffic |
easily scalable |
load distribution |
grouping of documents |
visibility of cache |
| W3C httpd |
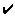 |
|
|
|
|
|
| DEC relay |
|
|
|
|
|
|
| Harvest |
|
|
|
|
|
|
| HTFP |
|
|
|
|
|
|
- Transparent: all of the caching systems are more or less transparent, in that they
are implemented in a proxy server and require only a one-time configuration in
order to be used.
- Reduce traffic: regardless of efficiency of caching mechanisms, all of these systems
reduce traffic to the outside network. Whenever a cache hit does occur, none of
these systems will normally send any data to the outside network. Further, if the
network allows it (e.g., no firewall), not everyone needs to go through the proxy
server to reduce the overall network traffic to the Internet. Simply by having a
reasonable portion of the network's users utilizing the cache, the network will
benefit from some reduction in the amount of Internet traffic.
- Ease of scalability: Because only Harvest and HTFP are already designed to be
distributed, these two can easily be scaled. Of course, the other systems can be
scaled by adding more disk space or memory to the proxy servers. However this is
not always practical or useful, especially in terms of server load. HTFP may have
a slight advantage in this category, since new machines can be added to scale the
cache size with minimal reconfiguration or thought of placement. One only needs
to change settings on the master proxy server. Harvest may require reorganization
of the hierarchy of the cache system.
. . .
7. Conclusions
HTFP represents a robust, scalable caching system that achieves many of the targeted design
criteria. It brings new ideas and features into a continually explored and developing field. In
designing this system, I considered many issues and alternatives. Often, as with any system,
HTFP had to sacrifice some elegance, simplicity, or transparency in order to maintain efficiency
and usability. With some of these sacrifices, and with the newness of some of HTFPąs features,
this caching system has some tradeoffs and possible negatives. It offers opportunities for further
development. Specifically, HTFP could benefit from examining the following hard problems:
- Reducing the chance of bottleneck at the master proxy server. Although the load
is distributed among a pool of proxy servers, all requests need to go through the
master proxy server; this represents a potential bottleneck and a possible source of
problems.
- Establishing a method to ignore cached entries and to force a proxy to retrieve
web pages from their sources upon client request.** This can help obtain stale versions of seemingly
valid data, such as documents containing server-side includes.
- Preventing duplicate storage of the same web page served by different servers or
the same server with different names (for example, espn.sportzone.com and
espnet.sportzone.com map to the same machines). This could be done via storing
pages under the IP address of their sources; this approach, of course, increases the
complexity of the system and may create additional Internet traffic during name
resolution.
Notes
* Based on scanning server logs for proxy-type specification
on both the author's Web servers and other Web servers.
** The DEC system accomplished this by modifying the
messages the web browser sends to the proxy; obviously, this is not user transparent or practical
for a large user base or for commercial, unmodifiable browsers.
References
[1] Measuring the Growth of the Web,
http://www.netgen.com/info/growth.html
[2] MIT Backbone Traffic Statistics, http://web.mit.edu/afs/net/admin/noc/backbone/quarterly
[3] Hypertext Transfer Protocol, HTTP/1.0,
http://www.w3.org/pub/WWW/Protocols/HTTP/1.0/spec.htm#GET
[4] The Harvest Cache and Httpd-Accelerator, http://excalibur.usc.edu/
[5] Host Distribution by Top-Level Domain Name,
http://www.nw.com/zone/WWW/dist-bynum.html
[6] Hypertext Transfer Protocol
/1.0.http://www.w3.org/pub/WWW/Protocols/HTTP/1.0/spec.html#POST
. . .

## Design and Feasibility Reports ##

[ Home | Table of Contents
| Writing Timeline | Index |
Help | Credits]